No matter how accustomed you are to it, presenting at a conference is always stressful. Many potential speakers find that worry and doubt prevent them from submitting that all important first talk. However, there are strategies that can help relieve this anxiety and greatly improve your odds of success. Garth Gilmour has been organising and presenting at conferences for over 20 years, mentoring first-time speakers for almost as long. In this webinar, he shares his top tips for success and discusses how to be prepared for whatever life throws at you on the day.
We hope you find these strategies helpful. Good luck with your first talk!
If you would like to share your experiences of delivering talks, and any tips of your own, please leave a comment below. We would also love to know if you would be interested in follow up events, such as on submitting to conferences, or even organising your own.
import java.io.File
fun main() {
val numbers = File("src/day1/input.txt")
.readLines()
.map(String::toInt)
}
将此代码放入 main 函数中,该函数是程序的入口点。 当您开始输入时,IntelliJ IDEA 会自动导入 java.io.File。
现在,我们只需迭代列表,然后对每个数字重复该迭代并检查和:
for (first in numbers) {
for (second in numbers) {
if (first + second == 2020) {
println(first * second)
return
}
}
}
将此代码放在 main 中,这样一来,找到所需数字时, return 会从 main 返回。
以类似的方式检查三个数字的和:
for (first in numbers) {
for (second in numbers) {
for (third in numbers) {
if (first + second + third == 2020) {
println(first * second * third)
return
}
}
}
}
val pair = numbers.mapNotNull { number ->
val complement = complements[number]
if (complement != null) Pair(number, complement) else null
}.firstOrNull()
fun List<Int>.findPairOfSum(sum: Int): Pair<Int, Int>? {
// Map: sum - x -> x
val complements = associateBy { sum - it }
return firstNotNullOfOrNull { number ->
val complement = complements[number]
if (complement != null) Pair(number, complement) else null
}
}
Remote collaboration has been around for a while and works very well for knowledge sharing, but software developers often need something more advanced than just screen sharing. Code With Me is a collaborative coding tool built into the majority of JetBrains IDEs. It’s a useful feature for those who teach and learn how to code, because it gives advanced accessibility to the feature-rich development environment. No matter where you are located, Code With Me can help you to level up your Kotlin skills!
Join us on Thursday, August 11, 2022, 5:00 pm – 6:00 pm UTC (check other timezones), for our free live webinar, Kotlin and Code With Me: Tips for Collaborative Programming, Teaching, and Learning.
During this livestream, Matt Ellis and Sebastian Aigner will share:
How to get started with Code With Me.
The most useful Code With Me features for guided mentoring sessions.
Matt Ellis is a developer advocate at JetBrains, working with lots of different IDEs and technologies such as the Unity and Unreal Engine game development tools in Rider, Code With Me for collaborative editing, and remote development with JetBrains Gateway. He has spent well over 20 years shipping software in various industries. He thoroughly enjoys working with IDEs and development tools, syntax trees, and source code analysis. Matt also works on Unity support in Rider and contributes to the popular IdeaVim plugin.
Sebastian Aigner
Having developed mobile, web, and server-side applications for clients during his time at the Technical University of Munich, Sebastian discovered his love for sharing knowledge. In the role of Developer Advocate at JetBrains, he now pioneers the teaching of Kotlin in universities and schools. Sebastian’s technical interests revolve around building networked applications and using Kotlin on a multitude of platforms.
Remote collaboration has been around for a while and works very well for knowledge sharing, but software developers often need something more advanced than just screen sharing. Code With Me is a collaborative coding tool built into the majority of JetBrains IDEs. It’s a useful feature for those who teach and learn how to code, because it gives advanced accessibility to the feature-rich development environment. No matter where you are located, Code With Me can help you to level up your Kotlin skills!
Join us on Thursday, August 11, 2022, 5:00 pm – 6:00 pm UTC (check other timezones), for our free live webinar, Kotlin and Code With Me: Tips for Collaborative Programming, Teaching, and Learning.
During this livestream, Matt Ellis and Sebastian Aigner will share:
How to get started with Code With Me.
The most useful Code With Me features for guided mentoring sessions.
Matt Ellis is a developer advocate at JetBrains, working with lots of different IDEs and technologies such as the Unity and Unreal Engine game development tools in Rider, Code With Me for collaborative editing, and remote development with JetBrains Gateway. He has spent well over 20 years shipping software in various industries. He thoroughly enjoys working with IDEs and development tools, syntax trees, and source code analysis. Matt also works on Unity support in Rider and contributes to the popular IdeaVim plugin.
Sebastian Aigner
Having developed mobile, web, and server-side applications for clients during his time at the Technical University of Munich, Sebastian discovered his love for sharing knowledge. In the role of Developer Advocate at JetBrains, he now pioneers the teaching of Kotlin in universities and schools. Sebastian’s technical interests revolve around building networked applications and using Kotlin on a multitude of platforms.
In this livestream, Dmitry will cover the following topics:
How a project-based, practice-oriented approach helps when learning programming.
Kotlin tracks on JetBrains Academy: Kotlin Basics, Kotlin Developer, Kotlin for Backend (preview), and First Glance at Android.
A closer look at the Kotlin Basics track: major topic segments in the Knowledge map, types of projects and topics, and track completion requirements.
A student’s perspective of completing the Kotlin Basics track: a graduate project from beginning to end.
An educator’s perspective: integrating the JetBrains Academy platform and Kotlin topics in university courses.
JetBrains IDEs and the EduTools plugin as tools for learners and teachers.
You can watch the livestream on YouTube or register here to get a reminder. The livestream will include a Q&A session where you’ll be able to discuss teaching and learning Kotlin topics with Dmitry and the host from the Kotlin team.
Dmitry is a software engineer, technical writer, and JetBrains Academy expert.
Dmitry writes articles about software development on Medium and posts lessons on Hyperskill, focusing on the safety and simplicity of networking and other asynchronous operations.
He is currently working on a coroutines topic for the JetBrains Academy Kotlin Basics track.
His hobbies include surfing, motorcycles, and podcasting.
In this livestream, Dmitry will cover the following topics:
How a project-based, practice-oriented approach helps when learning programming.
Kotlin tracks on JetBrains Academy: Kotlin Basics, Kotlin Developer, Kotlin for Backend (preview), and First Glance at Android.
A closer look at the Kotlin Basics track: major topic segments in the Knowledge map, types of projects and topics, and track completion requirements.
A student’s perspective of completing the Kotlin Basics track: a graduate project from beginning to end.
An educator’s perspective: integrating the JetBrains Academy platform and Kotlin topics in university courses.
JetBrains IDEs and the EduTools plugin as tools for learners and teachers.
You can watch the livestream on YouTube or register here to get a reminder. The livestream will include a Q&A session where you’ll be able to discuss teaching and learning Kotlin topics with Dmitry and the host from the Kotlin team.
Dmitry is a software engineer, technical writer, and JetBrains Academy expert.
Dmitry writes articles about software development on Medium and posts lessons on Hyperskill, focusing on the safety and simplicity of networking and other asynchronous operations.
He is currently working on a coroutines topic for the JetBrains Academy Kotlin Basics track.
His hobbies include surfing, motorcycles, and podcasting.
“Always bet on the future. If you’re not willing to, it’s hard to enjoy a life in technology.”
Geoffrey Challen
On November 23, we held a ‘Teaching Introductory Computer Science in Kotlin’ webinar, featuring Geoffrey Challen, Teaching Associate Professor at the University of Illinois at Urbana-Champaign. He is the lead instructor for a course, which is now the largest introductory computer science course to offer Kotlin as a language option, with an impressive 1300 students.
According to Geoffrey, Kotlin is an ideal choice for a first programming language to learn as it maximizes the fun and minimizes the frustration.
In this post, we want to share with you a recap of the questions and answers from the webinar.
Q1: It gets a bit heavy for students to set up an IDE to start with Kotlin. I use Kotlin playground to teach them but is there any syntax highlighting REPL for Kotlin?
A1: A lot of the work that we do for my class is done in the browser. I think IDEs are great and the JetBrains IDEs for Java and for Kotlin are fantastic, as well as Android Studio, which is built on top of the same technology.
For people that are just getting started, the IDE can get in the way. So we have students work in this very stripped-down playground environment where there is no syntax highlighting.
In terms of things like auto-completion, I tend to think that students do better starting out without those helpful things and I encourage them to type the code themselves. The problems that we’re having students do for my class on a daily basis are at most 10 or 20 lines of code. Type the code yourself and get used to doing that type of thing without heavy reliance on the IDE.
I was working with someone the other day and they were trying to set up an empty list and on the right side of the initialization, instead of writing new array lists, they wrote new lists and then they hit “Return”. And of course, the IDE thinks that you want to create a new anonymous implementation of the list class and so it spits out this one-hundred-line-long prototype implementation. And the student has no idea what just went wrong. And it’s just a small mistake that is easy to make. I’ve made it before.
But I use an IDE all the time, so I certainly don’t want to claim that they’re not useful. They’re tremendously helpful. But I think for people who are just getting started, they’re certainly not required, and besides, I wouldn’t want to use a language that really required an IDE.
It’s interesting with Kotlin because I have seen people say the language really seems to require an IDE. And our experience has been that that’s not the case. Our students are able to write Kotlin code fine in an environment with limited syntax highlighting and no auto-completion.
Once we start working on Android, we do have them use Android Studio obviously, because there’s no other way to do it. I have always been really impressed with how well it works, and I think it’s just a testament to Android Studio and how good the documentation is. I’ve got 1300 students in my class, and I would say 99% of them are able to set up Android Studio on their machine without any problems. I think the fact that this is a tool that’s used by so many developers just means that the documentation is awesome and the tutorials for getting started are great.
Q2: What’s the knock-on effect for other modules here? E.g. If students in CS1 choose Kotlin, does this force other faculty to allow it for coursework in their modules?
A2: One of the things that gives me a little bit of freedom in my CS1 course is that I don’t have a lot of downstream dependencies. At the University of Illinois, when students start in my class, they take either Java or Kotlin and then they end up grinding through multiple semesters of C++. From the perspective of fun, I have a lot of concerns about that language choice and I’ve been talking about this with my colleagues. There’s not a second-semester course that’s also in Java. I think the next course in the department that’s in Java is actually at the 400 level so it’s multiple years downstream.
When you think about how curricula work, at some point you want to stop teaching languages. We teach languages for the first couple of years, but once students get to the third year or fourth year of the program, I think they should be expected to take a course and just pick up a new language as they need.
So I hope that in some of our more advanced courses that use Java – one of those courses actually does do Android Development – I would hope that they would be able to say “Okay fine, we’ll do Kotlin too, why not?”
Q3: When using Android, how do you handle the balance between spending time on CS fundamentals and/or Android specificities?
A3: I feel like the concern here might be that students are getting distracted by the fun of Android programming and they’re not learning basic computer science principles that you want them to learn in a CS1 course.
So, first of all, my experience is that we’ve been able to do both. We do a lot of foundational computer science concepts including sorting algorithms and recursion. We actually added some content on graphs this semester for the first time. And students had a lot of fun with it. Then they’re also doing Android programming alongside it. So I think that with a course that’s ambitious enough you can get this to work. I’ve had some people look at my class and say: “You guys are covering a lot!”
We see very healthy numbers when we look at final grades and when we look at things like drop rates. So it certainly isn’t being done at the expense of the students in the class, particularly the students who come in with no experience. We bring them along but I think there are some intro courses that aren’t quite doing enough.
We’ve been using Android now for several years in the class. I do think that our Android assignments had gotten a little bit integration-heavy, focused on challenges involving getting two parts of the app to work together properly, as opposed to core CS concepts.
One of the things we’ve done this semester is we actually have more components of the Android project that students do that are really basic programming tasks and that really do push on core computer science competencies like the ability to use basic data structures and the ability to implement basic algorithms. We have students doing some work where it’s a part of the Android project. We end up using it either in the UI or in some other way. But really it’s almost like a problem that you could take out of Android and assign in a completely different context that just involves things like working with maps, understanding how to traverse a data structure, how to transform a data structure into a slightly different form, etc.
One of the final steps we are having the student do is essentially graph traversal. It’s in the context of this data set that we’ve given them that they’re using to do other things with the UI. But the core algorithm that we’re having them implement is graph traversal.
There is an opportunity to have some overlap there, where you’re not showing students how to build an app, you’re also continuing to give them practice with core computer science competencies.
Q4: I don’t think it’s good to teach Java & Kotlin at the same time. Students who are trying to understand a concept and need to remember two pieces of syntax and will get confused about which is which.
A4: I think there’s a little bit of a misconception underlying that question. Students don’t take the class in both languages. Students choose one language and then a student that chooses Kotlin can take the course and never even see a piece of Java.
One of the things that’s made this possible is this big restructuring of the course we did during the pandemic. The class is still being taught asynchronously online, so I don’t lecture. I used to be on stage in the largest auditorium on campus three times a week teaching students Java. I don’t do that anymore.
We took the course and completely redesigned it around this daily lesson model. If you’re a Java student in my class, you wake up, you go to the lessons page, you do the lesson – it’s in Java, you finish the problem – it’s in Java, you show up to take your weekly quiz – it’s in Java, you open up your project – it’s in Java. Some of the students are peeking at the other languages, I’m sure. So if you’re a Java student and you’re done with your lesson and you want to see the same concepts in Kotlin, you can do that.
Otherwise, if you were trying to do this as part of a more traditional course, I think it would create some problems. If you were teaching a course like this in two languages, I do think that you would choose ones that were more syntactically different.
I think we might be one of the only courses – we’re certainly one of the biggest, highest-profile courses – that’s offering students the option of languages.
Q5: How does such a large course work? Do you get any one-on-one time with your students?
A5: I don’t necessarily do a lot of that. I spend my time creating the materials, working with my staff, and keeping all of our systems online. We do have – and again this is something we created during the pandemic – a system that is built through the website where students can get one-on-one help from staff. I have a large core staff, about 40 or 50 paid staff members, and then a bunch of students that are doing it for course credit to learn how to be a course assistant.
Normally pretty much from 9 am to 11 pm we have somebody on our help site. A student who is struggling with that day’s lesson or needs help with the homework or with the Android project can go on the help site and receive assistance from a staff member. From time to time I jump on the help site as a staff member, partly because it’s fun. I enjoy helping students. It also helps me understand how students are doing. I see what people are struggling with. But the students are typically pretty surprised when I end up helping them.
One of the reasons it works so well is because I think our online materials are already really good. 90% of the students almost never use our help site. That’s great because they’re learning material from the lessons, from our interactive materials. And then it also means that it’s easier to help the other students because the staff-to-student ratio is better. The whole system works really well. I’m pretty proud of it.
The pandemic has been such a difficult event for so many people. I think it’s been difficult to talk about some of the good things that have come out of it. But in the past, if a student needed help, we said, “Oh we have office hours, come to the computer science building, down to the basement, and we’ll help you.” It might take them an hour to go back and forth for five minutes’ worth of help.
Next semester the plan is to restart some in-person activities, but we’re definitely going to keep this site running, because, for students that have quick questions, it’s awesome.
Q6: Have you considered using the Kotlin EduTools plugin to solve problems in the IDE?
A6: I’ll admit, I tend to be sort of bad at using other people’s things. I enjoy creating my own stuff. As I was prepping for this, I was looking around and I was like “Oh, you guys do have these amazing resources.” One of the things that’s important for me from the perspective of an educator is being able to generate content.
The problems that we’ve created for our students are super valuable, but they do take time and energy to create and so does the system that we’ve built to author those problems, maybe we could get it to fit in with the plugin for Kotlin. We could look into it.
Like I said, I’m also not 100% convinced that I want students working in an IDE right away, because I do think there are some pedagogical advantages to having to type the code out yourself, not being able to rely on all the autocomplete and suggestions.
One of the things that’s at least fun for me as an educator is that you realize how much the experience of working with computers has changed you. The kinds of mistakes that my students have a really hard time seeing, like the difference between a single equals and a double equals. I can see that from 30 feet away because I’ve just been looking at code for too long.
I think working in a simplified environment helps students instill some of these abilities, and then for doing a real project, use an IDE. I mean, everybody does this. Like I said, I use them all the time. I don’t do any programming outside of it. I try to do as little as possible outside of an IDE environment because I want all those benefits.
But I think there’s a question about how to bootstrap students in a good way that gives them the foundation for success. For me, having them start with the IDE is not always the best thing.
I think IntelliJ IDEA is a fantastic IDE. The other thing to keep in mind too is that these are complex pieces of software. As soon as you open up one of these IDEs, it’s like you’re at the controls of a 747. I think the IntelliJ-based IDEs do a great job of organizing information and trying to simplify stuff, but it’s still a power tool. You don’t take someone who’s trying to learn how to fly a plane and put them in the cockpit of a 747. That’s not where you start. I like just having them understand “Okay there’s a text box on the website that you’re typing into, and that’s all you need to worry about,” as much as I like IDEs for real, more advanced, complicated programming.
Q7: Do you know if some of the students stick with Kotlin after the courses for hobby or even professional settings?
A7: The first course I taught in Kotlin was to a subset of students in Spring 2019. So it’ll take a couple of years to get a sense of how things work as students go through the pipeline.
One of the things that you learn as an instructor is that there are these really long feedback loops that happen in computer science programs.
I’ll give an example: When I started teaching the course, I started requiring that students (this was in Java, in spring 2019) follow the Checkstyle guidelines that have to do with things like spacing brace placement. There was a massive amount of howling that went up from the students in the first semester: “Why are you grading me on this? It has nothing to do with correctness.”
But semester after semester the volume just went down, because students realize that this thing actually paid off downstream. It really helped them in the next courses.
One of the reasons that we use Checkstyle is as follows: Imagine you’re a staff member on my help site. You’re working with one student for five minutes, another student for five minutes, another student for five minutes – every piece of code looks different, if every one of them has different conventions…
Indentation is obviously the biggest problem with student code. You can’t read code if it’s not indented properly. If everything looks different, there’s a lot of extra mental overhead for you to just help the student. So one of the nice things about Checkstyle guidelines, which we use now for Kotlin, is that everything looks the same and that really helps the staff. I want the staff to be helping the student with the computational thinking that they’re struggling with.
Ask me in a couple of years right after these students have moved their way deeper into the program, they’ve had a chance to interview for jobs.
As Kotlin becomes more well established for programming interviews and stuff like that, I think that’ll help. I think right now, though, if you learn Kotlin, you might have a little bit of an advantage for some jobs, if the job wants someone who knows Kotlin.
You guys have made some great progress at getting Kotlin taught in computer science programs but it’s still far from common. So if you’re going up for an internship and the internship wants somebody with Kotlin experience and you’re that person, you’re not going to have a lot of competition. So hopefully that’ll help, but the long-term impact of this we’ll see. It’s going to be fun to watch.
Q8: How can I gain admission to this university?
A8: The admission to the Computer Science program here is really selective. I think we accept around 10% of applicants at this point. The university does offer a variety of mixed degrees. We have a degree in CS plus Statistics, we have a degree in CS plus Crop Sciences. This is an agricultural university so there’s actually some really cool agricultural tech that’s being built right now that you can see out in the fields around here sometimes.
Also, if you take one of those programs, you get a fantastic grounding in computer science combined with complementary study in some other field.
In CS plus Statistics you get all the computer science stuff but then you also get this rigorous training in data analysis. I think that those are the two modern superpowers: how to build things using computer science and then work with data.
But Illinois is a top-five/top-three school depending on how you rank. It is tough to get in here. I’m not gonna sugarcoat that.
Q9: Is there any specific CS concept that you have found easier to teach students with Kotlin (in comparison to Java)?
A9: What we’ve done so far with Kotlin is that we took a course that was in Java and we’ve run a Kotlin course alongside of it. The results end up being a little bit handicapped by Java. For example, when I’m designing our Android project, I have a solution set that I’m working on and I always work on the Java solution set first, because the Kotlin version is going to be a lot nicer. If you start with Kotlin it’s easy to build something that’s too hard to do in Java. So I always start with Java and then I translate it to Kotlin for the Kotlin solution set.
There’s a couple of things about Kotlin that I think are super nice. Working with containers in Kotlin: lists, sets, maps – is a massive improvement over Java. You don’t have five imports that you need to do.
Initialization syntax, bracket syntax is awesome and I talked a little bit about this in my blog post. I have mixed feelings about operator overloading in general, but the ability to support things like bracket syntax for lists and maps is awesome. I think that’s one of the areas where Kotlin has a massive advantage for Intro CS.
If I was teaching the course in Kotlin, I would do more with streams and stream processing, pipeline-type, higher-order programming concepts.
We do those very very late, and it’s really kind of enrichment at that point. Part of the reason for that is that I don’t think I could write a stream pipeline in Java without an IDE because the syntax is just weird. I want a list and there’s some collectors to lists and I remember how to do it so I just start typing to lists and I hope that the IDE helps me out. Whereas Kotlin syntax for map-reduce-filter type stuff is just awesome.
If we were doing the course in Kotlin and didn’t have Java alongside, we’d probably do more functional programming ideas, more work with higher-order programming, we’d talk a little bit more about things like maps and first-class functions and function wrappers.
It’s stuff you can do in Java, but the syntactic issues start to raise their ugly heads there, so that’s something that we don’t do as much.
But I think if we started with Kotlin and worked that way, there probably are some pretty substantial differences that would arise.
Q10: Is it possible to deploy your own version of the online learning platform you built, for courses at other places? Is it open-source or did you consider making it open source?
A10: We’re working on this. First of all, if you’re interested in this type of project please let me know. It’s always easiest for me to work on something when I have the knowledge that there’s someone who’s actually excited about using it.
The current course website was developed very quickly during the pandemic and I was learning a lot of things as I went. So I don’t have any plans to publish it. It also has a lot of other materials in it that I don’t want to share. It has all the quiz contents for my class and I can’t publish those because they have solutions in them.
If you’re excited about this, I would love to have a class that I maintain with a collaborator. Particularly at another institution, so if someone else said, “Hey, I’d like to teach Kotlin. Let’s work on materials together,” the materials are designed so that anybody can contribute explanations and content.
So if you were at some other university and I was here and the courses were similar enough in structure, you could record a bunch of your materials, my students could see you explaining stuff, your students could see me explaining stuff – and my staff and everybody else who’s already contributed. That would be pretty cool. I’d be super excited about that.
In my opinion, there isn’t enough cross-institutional collaboration in this type of way.
The structure is amenable to this type of collaboration. You can make the course feel like yours; I can still make the course feel like it’s mine. But students get the best of both worlds, where they have more backup content, and more voices.
That’s the other thing, too, that I’m really passionate about: making the course speak with a more diverse set of voices. I’m hoping that, in a couple of years from now, when students come and take the class, they hear a lot less from me and they hear a lot more from my staff, and a lot more from a diverse set of collaborators.
As always, we’d love to hear from you. Leave your comments here, send us a message about your educational experience to education@kotlinlang.org, or drop us a message in our Kotlinlang Slack #education channel. Thanks!
In this webinar, Geoffrey will share his experience using Kotlin and explain why he chose it for teaching introductory programming. Geoffrey is the lead instructor for CS 124 – Intro to Computer Science at the University of Illinois, which is now the largest introductory computer science course to offer Kotlin as a language option.
You can watch the webinar on YouTube and register here to get a reminder. The webinar will include a Q&A session where you’ll be able to discuss anything you are interested in with Geoffrey and the host from the Kotlin team.
Kotlin’s popularity is increasing in many fields, including academia. One of the reasons for this development is that educators consider it to be a good language for teaching introductory computer science. According to Geoffrey Challen, Kotlin is an ideal choice for a first programming language. Сombining the type safety of Java with Python’s clean and elegant syntax, it provides better support for null-safety and functional programming patterns than either of those languages. Great for creating Android apps, backend servers, and web applications, Kotlin also represents an ideal first language for introducing students to the incredible creative potential of programming and computer science.
Geoffrey is a Teaching Associate Professor at the University of Illinois. His professional goal is to teach computer science to as many people as possible and to inspire them to use their skills to change the world for the better.
This post continues our “Idiomatic Kotlin” series and provides the solution for the Advent of Code Day 9* challenge. While solving it, we’ll look into different ways to manipulate lists in Kotlin.
Day 9. Encoding error, part I
We need to attack a weakness in data encrypted with the eXchange-Masking Addition System (XMAS)! The data is a list of numbers, and we need to find the first number in the list (starting from the 26th) that is not the sum of any 2 of the 25 numbers before it. We’ll call the number valid if it can be presented as a sum of two numbers from the previous sublist, and invalid otherwise. Two numbers that sum to a valid number must be different from each other.
If the first 25 numbers are 1 through 25 in a random order, the next number must be the sum of two of those numbers to be valid:
26 would be a valid next number, as it could be 1 plus 25 (or many other pairs, like 2 and 24).
49 would be a valid next number, as it is the sum of 24 and 25.
100 would not be valid; no two of the previous 25 numbers sum to 100.
50 would also not be valid; although 25 appears in the previous 25 numbers, the two numbers in the pair must be different.
Solution, part I
Let’s solve the task in Kotlin! For a start, let’s implement a function that checks whether a given list contains a pair of numbers that sum up to a given number. We’ll later use this function to check whether a given number is valid by passing this number and the list of the previous 25 numbers as arguments.
For convenience, we can define the function as an extension on a List of Long numbers. We need to iterate over all the elements in the list, looking for the two with the given sum. The first naive attempt will be using forEach (we call it on this implicit receiver, our list of numbers) to iterate through the elements twice:
fun List<Long>.hasPairOfSumV1(sum: Long): Boolean {
forEach { first ->
forEach { second ->
if (first + second == sum) return true
}
}
return false
}
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSumV1(26)) // true; 26 = 1 + 25
println(numbers.hasPairOfSumV1(49)) // true; 49 = 24 + 25
println(numbers.hasPairOfSumV1(100)) // false
// This is wrong:
println(numbers.hasPairOfSumV1(50)) // true; 50 = 25 * 2
}
But this solution is wrong! Using this approach, first and second might refer to the same element. But as we remember from the task description, two numbers that sum to a valid number must be different from each other.
To fix that, we can iterate over a list of elements with indices and make sure that the indices of two elements are different:
fun List<Long>.hasPairOfSumV2(sum: Long): Boolean {
forEachIndexed { i, first ->
forEachIndexed { j, second ->
if (i != j && first + second == sum) return true
}
}
return false
}
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSumV2(50)) // false
}
This way, if first and second both refer to 25, they have the same indices, so they are no longer interpreted as a correct pair.
We can rewrite this code and delegate the logic for finding the necessary element to Kotlin library functions. For this case, any does the job. It returns true if the list contains an element that satisfies the given condition:
//sampleStart
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
//sampleEnd
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSum(50)) // false
}
Our final version of the hasPairOfSum function uses any to iterate through indices instead of elements and checks for a pair that meets the condition. indices is an extension property on Collection that returns an integer range of collection indices, 0..size - 1; we call it on this implicit receiver, our list of numbers.
Finding an invalid number
Let’s implement a function that looks for an invalid number, one that is not the sum of two of the 25 numbers before it.
Before we start, let’s store the group size, 25, as a constant. We have a sample input that we can check our solution against which uses the group size 5 instead, so it’s much more convenient to change this constant in one place:
const val GROUP_SIZE = 25
We define the group size as const val and make it a compile-time constant, which means it’ll be replaced with the actual value at compile time. Indeed, if you use this constant (e.g. in a range GROUP_SIZE..lastIndex) and look at the bytecode, you’ll no longer be able to find the GROUP_SIZE property. Its usage will have been replaced with the constant 25.
For convenience, we can again define the findInvalidNumber function as an extension function on List. Let’s first implement it more directly, and then rewrite it using the power of standard library functions.
We use the example provided with the problem, where every number but one is the sum of two of the previous 5 numbers; the only number that does not follow this rule is 127:
//sampleStart
const val GROUP_SIZE = 5
fun List<Long>.findInvalidNumberV1(): Long? {
for (index in (GROUP_SIZE + 1)..lastIndex) {
val prevGroup = subList(index - GROUP_SIZE, index)
if (!prevGroup.hasPairOfSum(sum = this[index])) {
return this[index]
}
}
return null
}
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV1()) // 127
}
//sampleEnd
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
Because we need to find the first number in the input list that satisfies our condition starting from the 26th, we iterate over all indices starting from GROUP_SIZE + 1 up to the last index, and for each corresponding element check whether it’s invalid. prevGroup contains exactly GROUP_SIZE elements, and we run hasPairOfSum on it, providing the current element as the sum to check. If we find an invalid element, we return it.
You may think that the sublist() function creates the sublists and copies the list content, but it doesn’t! It merely creates a view. By using it, we avoid having to create many intermediate sublists!
We can rewrite this code using the firstOrNull library function. It finds the first element that satisfies the given condition. This allows us to find the index of the invalid number. Then we use let to return the element staying at the found position:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumberV2(): Long? =
((GROUP_SIZE + 1)..lastIndex)
.firstOrNull { index ->
val prevGroup = subList(index - GROUP_SIZE, index)
!prevGroup.hasPairOfSum(sum = this[index])
}
?.let { this[it] }
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV2()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
Note how we use safe access together with let to transform the index if one was found. Otherwise null is returned.
Using ‘windowed’
To improve readability, we can follow a slightly different approach. Instead of iterating over indices by hand and constructing the necessary sublists, we use a library function that does the job for us.
The Kotlin standard library has the windowed function, which returns a list or a sequence of snapshots of a window of a given size. This window “slides” along the given collection or sequence, moving by one element each step:
Here we build sublists, that is, snapshots, of size 2 and 3. To see more examples of how to use windowed and other advanced operations on collections, check out this video.
This function is perfectly suited to our challenge, as it can build sublists of the required size automatically for us. Let’s rewrite findInvalidNumber once more:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumberV3(): Long? =
windowed(GROUP_SIZE + 1)
.firstOrNull { window ->
val prevGroup = window.dropLast(1)
!prevGroup.hasPairOfSum(sum = window.last())
}
?.last()
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV3()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
To have both the previous group and the current number, we use a window with the size GROUP_SIZE + 1. The first GROUP_SIZE elements form the necessary sublist to check, while the last element is the current number. If we find a sublist that satisfies the given condition, its last element is the result.
Note about the difference between sublist and windowed functions
Note, however, that unlike sublist(), which creates a view of the existing list, the windowed() function builds all the intermediate lists. Though using it improves readability, it results in some performance drawbacks. For parts of the code that are not performance-critical, these drawbacks usually are not noticeable. On the JVM, the garbage collector is very effective at collecting such short-lived objects. It’s nevertheless useful to know about these nuanced differences between the two functions!
There’s also an overloaded version of the windowed() function that takes lambda as an argument describing how to transform each window. This version doesn’t create new sublists to pass as lambda arguments. Instead, it passes “ephemeral” sublists (somewhat similar to sublist() views) that are valid only inside the lambda. You should not store such a sublist or allow it to escape unless you’ve made a snapshot of it:
fun main() {
val list = listOf('a', 'b', 'c', 'd', 'e')
// Intermediate lists are created:
println(list.windowed(2).map { it.joinToString("") })
// Lists passed to lambda are "ephemeral",
// they are only valid inside this lambda:
println(list.windowed(2) { it.joinToString("") })
// You should make a copy of a window sublist
// to store it or pass further:
var firstWindowRef: List<Char>? = null
var firstWindowCopy: List<Char>? = null
list.windowed(2) {
if (it.first() == 'a') {
firstWindowRef = it // Don't do this!
firstWindowCopy = it.toList()
}
it.joinToString("")
}
println("Ref: $firstWindowRef") // [d, e]
println("Copy: $firstWindowCopy") // [a, b]
}
If you try to store the very first window [a, b] by copying the reference, you see that by the end of the iterations this reference contains different data, the last window. To get the first window, you need to copy the content.
A function with similar optimization might be added in the future for Sequences, see KT-48800 for details.
We can further improve our findInvalidNumber function by using sequences instead of lists. In Kotlin, Sequence provides a lazy way of computation. In the current solution, windowed eagerly returns the result, the full list of windows. If the required element is found in the very first list, it’s not efficient. The change to Sequence causes the result to be evaluated lazily, which means the snapshots are built only when they’re actually needed.
The change to sequences only requires one line. We convert a list to a sequence before performing any further operations:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumber(): Long? =
asSequence()
.windowed(GROUP_SIZE + 1)
.firstOrNull { window ->
val prevGroup = window.dropLast(1)
!prevGroup.hasPairOfSum(sum = window.last())
}
?.last()
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumber()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
That’s it! We’ve improved the solution from the very first version, making it more “idiomatic” along the way.
The last thing to do is to get the result for our challenge. We read the input, convert it to a list of numbers, and display the invalid one:
fun main() {
val numbers = File("src/day09/input.txt")
.readLines()
.map { it.toLong() }
val invalidNumber = numbers.findInvalidNumber()
println(invalidNumber)
}
For the sample input, the answer is 127, and for real input, the answer is also correct! Let’s now move on to solve the second part of the task.
Encoding error, part II
The second part of the task requires us to use the invalid number we just found. We need to find a contiguous set of at least two numbers in the list which sum up to this invalid number. The result we are looking for is the sum of the smallest and largest number in this contiguous range.
For the sample list, we need to find a contiguous list which sums to 127:
In this list, adding up all of the numbers from 15 through 40 produces 127. To find the result, we add together the smallest and largest number in this contiguous range; in this example, these are 15 and 47, producing 62.
Solution, part II
We need to find a sublist in a list with the given sum of its elements. Let’s first implement this function in a straightforward manner, then rewrite the same logic using library functions. We’ll discuss whether the windowed function from the previous part can help us here as well, and finally we’ll identify a more efficient solution.
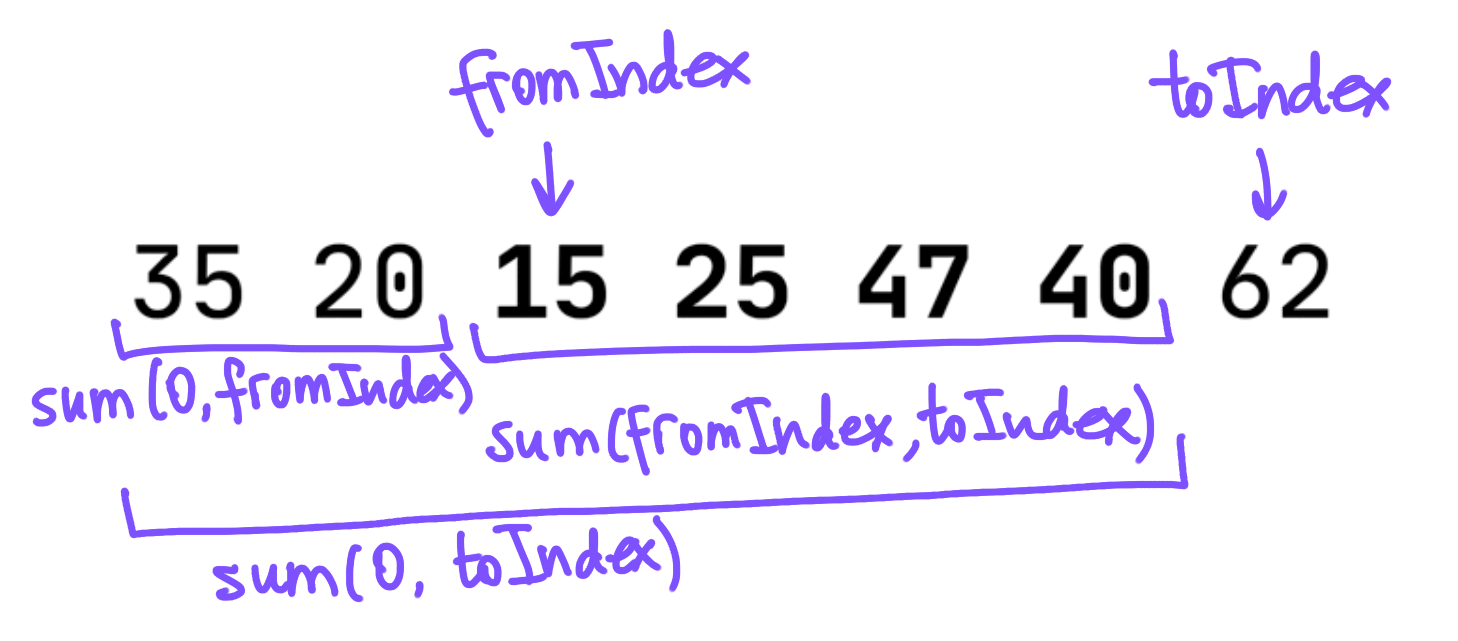
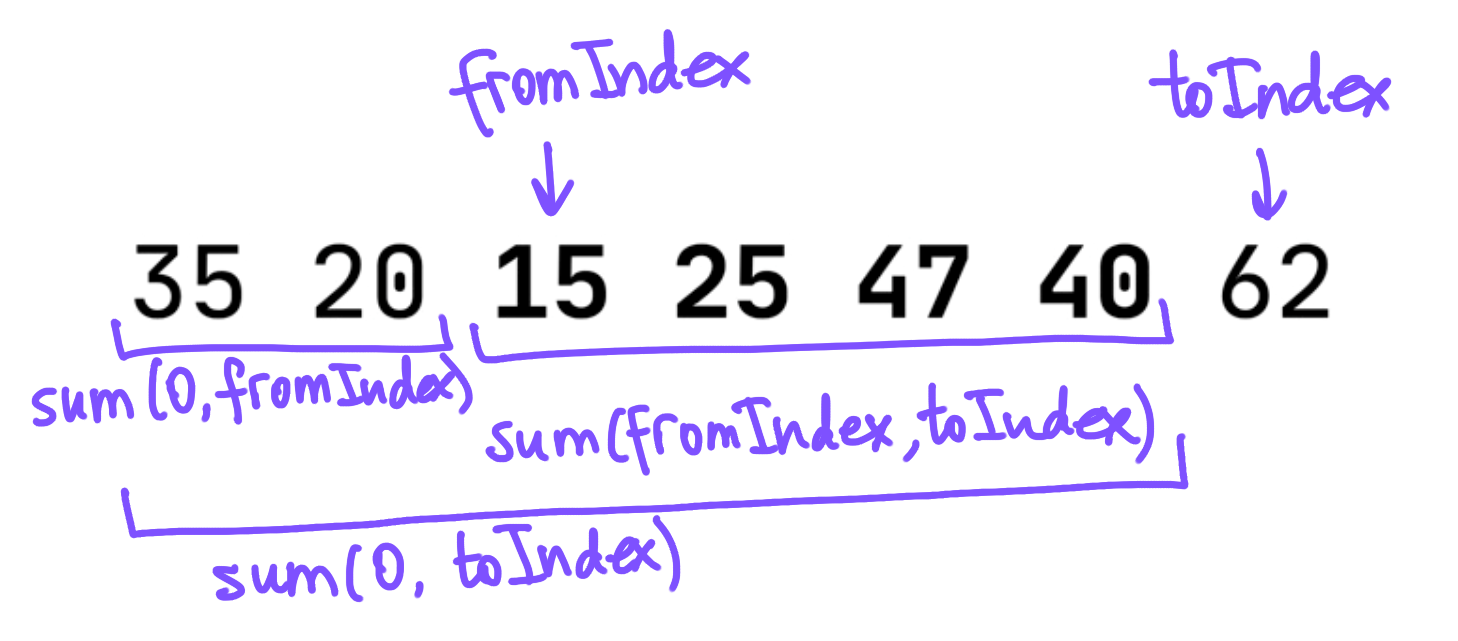
To check the sum of every contiguous sublist of a given list, we try all the options for the list’s start and end indices, build each sublist, and calculate its sum. fromIndex belongs to a full range of indices, while toIndex should be greater than fromIndex and shouldn’t exceed the list size (the toIndex argument defines an exclusive, not inclusive, upper bound):
fun List<Long>.findSublistOfSumV1(targetSum: Long): List<Long>? {
for (fromIndex in indices) {
for (toIndex in (fromIndex + 1)..size) {
val subList = subList(fromIndex, toIndex)
if (subList.sum() == targetSum) {
return subList
}
}
}
return null
}
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576
)
println(numbers.findSublistOfSumV1(127)) // [15, 25, 47, 40]
}
We can rewrite this logic using the firstNotNullOfOrNull function. Here, we iterate over possible values for fromIndex and for toIndex and look for the first value that satisfies the given condition:
The logic hasn’t changed, we’ve simply rewritten it using the firstNotNullOfOrNull. If a sublist with the required sum is found, it’s returned from both firstNotNullOfOrNull calls as the first found non-null value.
The takeIf function returns its receiver if it satisfies the given condition or null if it doesn’t. In this case, the takeIf call returns the found sublist if the sum of its elements is equal to the provided targetSum.
An alternative way to solve this problem is, for each possible sublist size, to build all the sublists of this size using the windowed function, and then check the sum of its elements:
As before, we convert the input list to a sequence to perform the operation in a lazy manner: each new sublist is created when it needs to be checked for sum.
All the functions we’ve considered so far work for the challenge input and give the correct answer, but they have one common disadvantage: they manipulate the sublists of all possible sizes, and for each one, calculate the sum. This approach isn’t the most efficient. We can do better, can’t we?
We can precalculate all the sums of sublists from the first element in the list to each element, and use these “prefix” sums to easily calculate the sum between any two elements. If we have the sum of elements from 0 to fromIndex, and the sum of elements from 0 to toIndex, the sum of the elements from fromIndex to toIndex can be found by subtracting the former from the latter:
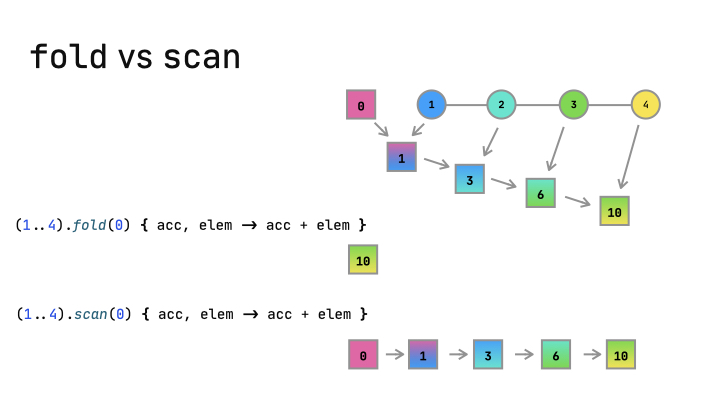
We need to precalculate the prefix sum for each element. We can use the standard library’s scan function for that! It also has another name, runningFold.
The fold and scan(runningFold) functions are related:
They both “accumulate” value starting with the initial value. On each step, they apply the provided operation to the current accumulator value and the next element.
fold returns only the final result, while scan(runningFold) returns the results for all the intermediate steps.
In this solution, we explicitly build only one sublist of the required sum to return it as the result.
Let’s now call the findSublistOfSum function to find the result for our initial challenge. After we found the invalid number in part I, we pass this value as an argument to the findSublistOfSum function, and then find the sum of the minimum and maximum values of the resulting list:
fun main() {
val numbers = File("src/day09/input.txt")
.readLines()
.map { it.toLong() }
val invalidNumber = numbers.findInvalidNumber()
?: error("All numbers are valid!")
println("Invalid number: $invalidNumber")
val sublist = numbers.findSublistOfSum(sum = invalidNumber)
?: error("No sublist is found!")
println(sublist.minOf { it } + sublist.maxOf { it })
}
Note how we use the error function to report an error and throw an exception in the event that one of our functions returns null. In AdventOfCode puzzles, we assume that the input is correct, but it’s still useful to handle errors properly.
That’s all! We’ve discussed the solution for the Day 9 AdventOfCode challenge and worked with the any, firstOrNull, firstNotNullOfOrNull, windowed, takeIf and scan functions, which exemplify a more idiomatic Kotlin style.
This post continues our “Idiomatic Kotlin” series and provides the solution for the Advent of Code Day 9* challenge. While solving it, we’ll look into different ways to manipulate lists in Kotlin.
Day 9. Encoding error, part I
We need to attack a weakness in data encrypted with the eXchange-Masking Addition System (XMAS)! The data is a list of numbers, and we need to find the first number in the list (starting from the 26th) that is not the sum of any 2 of the 25 numbers before it. We’ll call the number valid if it can be presented as a sum of two numbers from the previous sublist, and invalid otherwise. Two numbers that sum to a valid number must be different from each other.
If the first 25 numbers are 1 through 25 in a random order, the next number must be the sum of two of those numbers to be valid:
26 would be a valid next number, as it could be 1 plus 25 (or many other pairs, like 2 and 24).
49 would be a valid next number, as it is the sum of 24 and 25.
100 would not be valid; no two of the previous 25 numbers sum to 100.
50 would also not be valid; although 25 appears in the previous 25 numbers, the two numbers in the pair must be different.
Solution, part I
Let’s solve the task in Kotlin! For a start, let’s implement a function that checks whether a given list contains a pair of numbers that sum up to a given number. We’ll later use this function to check whether a given number is valid by passing this number and the list of the previous 25 numbers as arguments.
For convenience, we can define the function as an extension on a List of Long numbers. We need to iterate over all the elements in the list, looking for the two with the given sum. The first naive attempt will be using forEach (we call it on this implicit receiver, our list of numbers) to iterate through the elements twice:
fun List<Long>.hasPairOfSumV1(sum: Long): Boolean {
forEach { first ->
forEach { second ->
if (first + second == sum) return true
}
}
return false
}
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSumV1(26)) // true; 26 = 1 + 25
println(numbers.hasPairOfSumV1(49)) // true; 49 = 24 + 25
println(numbers.hasPairOfSumV1(100)) // false
// This is wrong:
println(numbers.hasPairOfSumV1(50)) // true; 50 = 25 * 2
}
But this solution is wrong! Using this approach, first and second might refer to the same element. But as we remember from the task description, two numbers that sum to a valid number must be different from each other.
To fix that, we can iterate over a list of elements with indices and make sure that the indices of two elements are different:
fun List<Long>.hasPairOfSumV2(sum: Long): Boolean {
forEachIndexed { i, first ->
forEachIndexed { j, second ->
if (i != j && first + second == sum) return true
}
}
return false
}
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSumV2(50)) // false
}
This way, if first and second both refer to 25, they have the same indices, so they are no longer interpreted as a correct pair.
We can rewrite this code and delegate the logic for finding the necessary element to Kotlin library functions. For this case, any does the job. It returns true if the list contains an element that satisfies the given condition:
//sampleStart
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
//sampleEnd
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSum(50)) // false
}
Our final version of the hasPairOfSum function uses any to iterate through indices instead of elements and checks for a pair that meets the condition. indices is an extension property on Collection that returns an integer range of collection indices, 0..size - 1; we call it on this implicit receiver, our list of numbers.
Finding an invalid number
Let’s implement a function that looks for an invalid number, one that is not the sum of two of the 25 numbers before it.
Before we start, let’s store the group size, 25, as a constant. We have a sample input that we can check our solution against which uses the group size 5 instead, so it’s much more convenient to change this constant in one place:
const val GROUP_SIZE = 25
We define the group size as const val and make it a compile-time constant, which means it’ll be replaced with the actual value at compile time. Indeed, if you use this constant (e.g. in a range GROUP_SIZE..lastIndex) and look at the bytecode, you’ll no longer be able to find the GROUP_SIZE property. Its usage will have been replaced with the constant 25.
For convenience, we can again define the findInvalidNumber function as an extension function on List. Let’s first implement it more directly, and then rewrite it using the power of standard library functions.
We use the example provided with the problem, where every number but one is the sum of two of the previous 5 numbers; the only number that does not follow this rule is 127:
//sampleStart
const val GROUP_SIZE = 5
fun List<Long>.findInvalidNumberV1(): Long? {
for (index in (GROUP_SIZE + 1)..lastIndex) {
val prevGroup = subList(index - GROUP_SIZE, index)
if (!prevGroup.hasPairOfSum(sum = this[index])) {
return this[index]
}
}
return null
}
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV1()) // 127
}
//sampleEnd
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
Because we need to find the first number in the input list that satisfies our condition starting from the 26th, we iterate over all indices starting from GROUP_SIZE + 1 up to the last index, and for each corresponding element check whether it’s invalid. prevGroup contains exactly GROUP_SIZE elements, and we run hasPairOfSum on it, providing the current element as the sum to check. If we find an invalid element, we return it.
You may think that the sublist() function creates the sublists and copies the list content, but it doesn’t! It merely creates a view. By using it, we avoid having to create many intermediate sublists!
We can rewrite this code using the firstOrNull library function. It finds the first element that satisfies the given condition. This allows us to find the index of the invalid number. Then we use let to return the element staying at the found position:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumberV2(): Long? =
((GROUP_SIZE + 1)..lastIndex)
.firstOrNull { index ->
val prevGroup = subList(index - GROUP_SIZE, index)
!prevGroup.hasPairOfSum(sum = this[index])
}
?.let { this[it] }
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV2()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
Note how we use safe access together with let to transform the index if one was found. Otherwise null is returned.
Using ‘windowed’
To improve readability, we can follow a slightly different approach. Instead of iterating over indices by hand and constructing the necessary sublists, we use a library function that does the job for us.
The Kotlin standard library has the windowed function, which returns a list or a sequence of snapshots of a window of a given size. This window “slides” along the given collection or sequence, moving by one element each step:
Here we build sublists, that is, snapshots, of size 2 and 3. To see more examples of how to use windowed and other advanced operations on collections, check out this video.
This function is perfectly suited to our challenge, as it can build sublists of the required size automatically for us. Let’s rewrite findInvalidNumber once more:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumberV3(): Long? =
windowed(GROUP_SIZE + 1)
.firstOrNull { window ->
val prevGroup = window.dropLast(1)
!prevGroup.hasPairOfSum(sum = window.last())
}
?.last()
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV3()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
To have both the previous group and the current number, we use a window with the size GROUP_SIZE + 1. The first GROUP_SIZE elements form the necessary sublist to check, while the last element is the current number. If we find a sublist that satisfies the given condition, its last element is the result.
Note about the difference between sublist and windowed functions
Note, however, that unlike sublist(), which creates a view of the existing list, the windowed() function builds all the intermediate lists. Though using it improves readability, it results in some performance drawbacks. For parts of the code that are not performance-critical, these drawbacks usually are not noticeable. On the JVM, the garbage collector is very effective at collecting such short-lived objects. It’s nevertheless useful to know about these nuanced differences between the two functions!
There’s also an overloaded version of the windowed() function that takes lambda as an argument describing how to transform each window. This version doesn’t create new sublists to pass as lambda arguments. Instead, it passes “ephemeral” sublists (somewhat similar to sublist() views) that are valid only inside the lambda. You should not store such a sublist or allow it to escape unless you’ve made a snapshot of it:
fun main() {
val list = listOf('a', 'b', 'c', 'd', 'e')
// Intermediate lists are created:
println(list.windowed(2).map { it.joinToString("") })
// Lists passed to lambda are "ephemeral",
// they are only valid inside this lambda:
println(list.windowed(2) { it.joinToString("") })
// You should make a copy of a window sublist
// to store it or pass further:
var firstWindowRef: List<Char>? = null
var firstWindowCopy: List<Char>? = null
list.windowed(2) {
if (it.first() == 'a') {
firstWindowRef = it // Don't do this!
firstWindowCopy = it.toList()
}
it.joinToString("")
}
println("Ref: $firstWindowRef") // [d, e]
println("Copy: $firstWindowCopy") // [a, b]
}
If you try to store the very first window [a, b] by copying the reference, you see that by the end of the iterations this reference contains different data, the last window. To get the first window, you need to copy the content.
A function with similar optimization might be added in the future for Sequences, see KT-48800 for details.
We can further improve our findInvalidNumber function by using sequences instead of lists. In Kotlin, Sequence provides a lazy way of computation. In the current solution, windowed eagerly returns the result, the full list of windows. If the required element is found in the very first list, it’s not efficient. The change to Sequence causes the result to be evaluated lazily, which means the snapshots are built only when they’re actually needed.
The change to sequences only requires one line. We convert a list to a sequence before performing any further operations:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumber(): Long? =
asSequence()
.windowed(GROUP_SIZE + 1)
.firstOrNull { window ->
val prevGroup = window.dropLast(1)
!prevGroup.hasPairOfSum(sum = window.last())
}
?.last()
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumber()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
That’s it! We’ve improved the solution from the very first version, making it more “idiomatic” along the way.
The last thing to do is to get the result for our challenge. We read the input, convert it to a list of numbers, and display the invalid one:
fun main() {
val numbers = File("src/day09/input.txt")
.readLines()
.map { it.toLong() }
val invalidNumber = numbers.findInvalidNumber()
println(invalidNumber)
}
For the sample input, the answer is 127, and for real input, the answer is also correct! Let’s now move on to solve the second part of the task.
Encoding error, part II
The second part of the task requires us to use the invalid number we just found. We need to find a contiguous set of at least two numbers in the list which sum up to this invalid number. The result we are looking for is the sum of the smallest and largest number in this contiguous range.
For the sample list, we need to find a contiguous list which sums to 127:
In this list, adding up all of the numbers from 15 through 40 produces 127. To find the result, we add together the smallest and largest number in this contiguous range; in this example, these are 15 and 47, producing 62.
Solution, part II
We need to find a sublist in a list with the given sum of its elements. Let’s first implement this function in a straightforward manner, then rewrite the same logic using library functions. We’ll discuss whether the windowed function from the previous part can help us here as well, and finally we’ll identify a more efficient solution.
To check the sum of every contiguous sublist of a given list, we try all the options for the list’s start and end indices, build each sublist, and calculate its sum. fromIndex belongs to a full range of indices, while toIndex should be greater than fromIndex and shouldn’t exceed the list size (the toIndex argument defines an exclusive, not inclusive, upper bound):
fun List<Long>.findSublistOfSumV1(targetSum: Long): List<Long>? {
for (fromIndex in indices) {
for (toIndex in (fromIndex + 1)..size) {
val subList = subList(fromIndex, toIndex)
if (subList.sum() == targetSum) {
return subList
}
}
}
return null
}
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576
)
println(numbers.findSublistOfSumV1(127)) // [15, 25, 47, 40]
}
We can rewrite this logic using the firstNotNullOfOrNull function. Here, we iterate over possible values for fromIndex and for toIndex and look for the first value that satisfies the given condition:
The logic hasn’t changed, we’ve simply rewritten it using the firstNotNullOfOrNull. If a sublist with the required sum is found, it’s returned from both firstNotNullOfOrNull calls as the first found non-null value.
The takeIf function returns its receiver if it satisfies the given condition or null if it doesn’t. In this case, the takeIf call returns the found sublist if the sum of its elements is equal to the provided targetSum.
An alternative way to solve this problem is, for each possible sublist size, to build all the sublists of this size using the windowed function, and then check the sum of its elements:
As before, we convert the input list to a sequence to perform the operation in a lazy manner: each new sublist is created when it needs to be checked for sum.
All the functions we’ve considered so far work for the challenge input and give the correct answer, but they have one common disadvantage: they manipulate the sublists of all possible sizes, and for each one, calculate the sum. This approach isn’t the most efficient. We can do better, can’t we?
We can precalculate all the sums of sublists from the first element in the list to each element, and use these “prefix” sums to easily calculate the sum between any two elements. If we have the sum of elements from 0 to fromIndex, and the sum of elements from 0 to toIndex, the sum of the elements from fromIndex to toIndex can be found by subtracting the former from the latter:
We need to precalculate the prefix sum for each element. We can use the standard library’s scan function for that! It also has another name, runningFold.
The fold and scan(runningFold) functions are related:
They both “accumulate” value starting with the initial value. On each step, they apply the provided operation to the current accumulator value and the next element.
fold returns only the final result, while scan(runningFold) returns the results for all the intermediate steps.
In this solution, we explicitly build only one sublist of the required sum to return it as the result.
Let’s now call the findSublistOfSum function to find the result for our initial challenge. After we found the invalid number in part I, we pass this value as an argument to the findSublistOfSum function, and then find the sum of the minimum and maximum values of the resulting list:
fun main() {
val numbers = File("src/day09/input.txt")
.readLines()
.map { it.toLong() }
val invalidNumber = numbers.findInvalidNumber()
?: error("All numbers are valid!")
println("Invalid number: $invalidNumber")
val sublist = numbers.findSublistOfSum(sum = invalidNumber)
?: error("No sublist is found!")
println(sublist.minOf { it } + sublist.maxOf { it })
}
Note how we use the error function to report an error and throw an exception in the event that one of our functions returns null. In AdventOfCode puzzles, we assume that the input is correct, but it’s still useful to handle errors properly.
That’s all! We’ve discussed the solution for the Day 9 AdventOfCode challenge and worked with the any, firstOrNull, firstNotNullOfOrNull, windowed, takeIf and scan functions, which exemplify a more idiomatic Kotlin style.
Today in “Idiomatic Kotlin”, we’re solving another Advent of Code challenge. We will be simulating, diagnosing, and fixing a small, made up game console! If you have ever wanted to implement your own virtual machine or emulator for an existing system like a game console or a retro computing device, you’ll find this issue particularly interesting!
As usual, a number of Kotlin features will help us achieve that goal, like sealed classes, sequences, and immutability.
A passenger on our flight hands us a little retro game console that won’t turn on. It somehow seems to be stuck in an infinite loop, executing the same program over and over again. We want to help them by fixing it!
To do so, we first need to run a simulation of the program on our own. At a later point, we want to fix the console so that it no longer gets stuck in a loop. Because the input for this challenge contains a lot of information, we’ll spend some time dissecting it together.
The input for our challenge is a bunch of instructions, which are executed by the gaming device. If you’ve ever delved into how computers work, you might recognize this as some kind of “Assembly Language” – essentially simple low-level instructions for a processor that are executed one after the other, top down, without all the fancy bells and whistles that higher-level languages offer:
By looking through the code and the problem description, we can identify three different types of instructions: nop, jmp, and acc, which always come with a numeric value. We can use the industry standard terms to refer to the parts of an instruction. The first part (nop / jmp / acc) is called the “opcode”. The second part of the instruction is called the “immediate value”.
Our problem statement gives us some hints about how to interpret the combination of opcodes and immediate values.
The nop (No Operation) instruction doesn’t do anything besides advance to the following instruction. We can also ignore its immediate value for the time being.
The jmp (Jump) instruction jumps a given number of instructions ahead or back, based on its immediate value.
The acc (Accumulator) instruction modifies the only real memory of our little device, its “accumulator” register, which can save the result of additions or subtractions, again based on the immediate value that follows.
Based on this understanding of the input for our challenge, we can make some deductions that help us model the machine in Kotlin.
The first one of those is that the current state of the machine can be fully described with two numbers:
The accumulator, which is the result of any calculations that we’ve made so far.
The index for the next instruction that we want to execute. In computing, this is called the “instruction pointer” or “program counter”.
This graphic shows that indeed, the only moving parts in our machine are the accumulator and the instruction pointer. For a step-by-step walkthrough, be sure to watch the video accompanying this blog post.
The second observation is that instructions behave just like functions that take an accumulator and instruction pointer as inputs and return a new accumulator and instruction pointer as outputs. This graphic shows how the acc instruction acts like a function, but the same applies for the nop and jmp instructions, as well:
We are now armed with the knowledge we need to actually implement a simulator for this device. To recap:
The input for our program is a number of instructions in a list (the “program”)
Each instruction in our program can modify two things:
The instruction pointer, which determines the next instruction to be executed
The accumulator, which stores a single number
Our device continuously reads the instruction and executes it based on its current state. This process continues until we end up with an instruction pointer that is outside the bounds of our program, indicating termination.
Building a device simulator
With our understanding of the puzzle input, let’s move on to what we need in order to successfully run the program we’re given as a puzzle input. Because we’re told this program is stuck in some kind of loop, the actual “answer” to the challenge is going to be the value of the accumulator immediately before we execute an instruction a second time.
Before we even think about how to detect loops in such a program, let’s start by building a small simulator for the device.
Modeling the machine and its instructions
The first step is to model the machine’s state and its instructions. We determined that the state of the machine can be fully described using two numbers: the instruction pointer and the accumulator. We can model this pair as an immutable data class:
data class MachineState(val ip: Int, val acc: Int)
We then need to define the three different types of instructions that the machine understands. To do so, let’s create a small class hierarchy to represent the different types of instructions. This will allow us to share some attributes across all instructions and distinguish between the different types of instructions that we may encounter.
Because we figured out that an instruction can take a machine state and return a new machine state, we will attach an action attribute to all instructions. The action attribute is a function that transforms one machine state into a new one:
sealed class Instruction(val action: (MachineState) -> MachineState)
We also mark the Instruction class as sealed, allowing us to create subclasses for it and ensuring that the compiler is aware of all the subclasses for our Instruction class.
The first subclass we can tackle is the nop instruction. As per its name (“No Operation”), it does nothing but move on to the next instruction. Expressed in terms of the action associated with this instruction, it creates a new MachineState with an instruction pointer that is incremented by one. The accumulator remains unchanged. We can use the typical lambda syntax here to define our “action” function. It receives the previous MachineState as the implicitly named parameter it.
Because all nop instructions behave the same, we can use the object keyword to create a singleton object for them, instead of creating a whole class for this instruction:
The next instruction is the jmp instruction. We recall that the behavior of the jmp instruction only changes the instruction pointer, because that’s the part of the machine state that determines what instruction to run next. How far ahead or back the jump goes is determined by the attached immediate value – the accumulator once again remains unchanged:
Lastly, we implement the acc instruction, which adds its immediate value to the accumulator and increments the instruction pointer so that the program continues running with the next instruction:
With this model for state and instructions in place, we can move on to running a list of instructions, one after the other – a whole program.
Let’s write up a function called execute, which does exactly that: It starts the device with an initial state, where both instruction pointer and accumulator are zero. It performs a loop for as long as our instruction pointer is valid. Inside the loop, we read the instruction at the current index from our list. We then apply the action that is associated with that instruction, and feed it the current state of the machine. This returns a new state of the machine, from which we can continue execution. We can also add a quick call to println to ensure that this code actually runs as we expect it to.
If the program behaves correctly, then at some point the instruction pointer should go out of bounds – indicating that the program terminated. In this case, we can return the latest state of the machine. This would be our “happy path”. The finished function looks like this:
fun execute(instructions: List<Instruction>): MachineState {
var state = MachineState(0, 0)
while (state.ip in instructions.indices) {
val nextInstruction = instructions[state.ip]
state = nextInstruction.action(state)
println(state)
}
println("No loop found - program terminates!")
return state
}
To see if the function actually works, let’s also add the functionality required to read our program from the input text file. If you’ve followed along with the series, you probably already have a good idea of how we approach this: We open the file, read all of the lines of text inside, and turn them into Instruction objects by applying the map function.
val instructions = File("src/day08/input.txt")
.readLines()
.map { Instruction(it) }
Of course, we also need to actually figure out what kind of Instruction objects we actually want. To do so, we can write a small factory function, that does two things:
It uses the split function to turn the full lines into the instruction names and their associated value
It uses a when statement to instantiate the appropriate class – either nop, acc, or jmp
Note that this is one of the few situations where the Kotlin style guide expressly allows us to start a function with an uppercase letter. What we’re writing here is a “factory function”, which is intentionally allowed to look similar to a constructor call.
fun Instruction(s: String): Instruction {
val (instr, immediate) = s.split(" ")
val value = immediate.toInt()
return when (instr) {
"nop" -> Nop
"acc" -> Acc(value)
"jmp" -> Jmp(value)
else -> error("Invalid opcode!")
}
}
With these helper functions added to our program, we are ready to run it, passing the list of instructions we just parsed to the execute function:
fun main() {
println(execute(instructions))
}
When we run the program, we quickly notice that it does not terminate. This makes sense – our challenge was to find where our program begins infinitely looping and to see what the last machine state is exactly before we enter the loop a second time. But – at the very least – we have confirmed that something really is wrong with the input code for our challenge!
Detecting cycles and solving part 1
We can easily retrofit a simple kind of cycle detection into our execute function. To figure out when we see an instruction for the second time, we keep track of each instruction index we’ve encountered so far and save it in a Set. Whenever we’re done executing an instruction, we check whether our new instruction pointer contains a value that we’ve seen before. This would indicate that an instruction will be executed for a second time, meaning we can just return the current state of the machine:
fun execute(instructions: List<Instruction>): MachineState {
var state = MachineState(0, 0)
val encounteredIndices = mutableSetOf<Int>()
while (state.ip in instructions.indices) {
val nextInstruction = instructions[state.ip]
state = nextInstruction.action(state)
if (state.ip in encounteredIndices) return state
encounteredIndices += state.ip
}
println("No loop found - program terminates!")
return state
}
Running our simulator again, our program successfully detects the loop, and returns the last machine state before the cycle would continue. We enter the accumulator value as returned by the function on adventofcode.com, and celebrate our first star for this challenge!
Solving part 2
In the second part of the challenge, we go beyond just finding an error, and try our hand at fixing the program we’ve been presented. We receive an important hint in the problem statement: exactly one instruction is the root cause for the infinite loop. Somewhere in the long list of instructions, one of the jmp instructions is supposed to be a nop instruction, or vice versa.
We can apply a rather straightforward approach to attempt a solution. To find out which instruction needs fixing, we generate all possible versions of the program where a nop has been exchanged with a jmp and the other way around. We can then run them all and see whether any of them terminate.
We can apply a small optimization here and base our solution on Kotlin’s sequences, which allow us to do the same calculations, but in a lazy manner. By using sequences, our code will only generate those adjusted programs that we actually need, until we’ve found a working version, and then it will terminate. Essentially, we create a mutated program, execute it, and see whether it terminates. If it doesn’t, we create the next mutation and run the check again.
We can write a function called generateAllMutations, which takes the original program as its input and returns a sequence of other program codes that have been modified. Each element of that sequence will be a full program, but with one instruction exchanged.
We use the sequence builder to create a “lazy collection” of programs, by creating working copies of the original program and exchanging the appropriate instructions at the correct indices. Instead of returning a list of programs at the end, we “yield” an individual value. That is, we hand over a value to the consumer of our sequence. When our program hits this point, our code here actually stops doing work – until the next value in the sequence is requested, at which point we run the next iteration of our loop. The whole function looks like this:
fun generateAllMutations(instructions: List<Instruction>) = sequence<List<Instruction>> {
for ((index, instruction) in instructions.withIndex()) {
val newProgram = instructions.toMutableList()
newProgram[index] = when (instruction) {
is Jmp -> Nop(instruction.value)
is Nop -> Jmp(instruction.value)
is Acc -> continue
}
yield(newProgram)
}
}
To make this code work, we need to make some adjustments to the model of our machine instructions. We now know that we need the immediate values of nop operations in order to generate the corresponding jmp instructions. Thus, we turn the nopobject back into a full class with its very own immediate value:
class Nop(val value: Int)
This also requires a small change in the Instruction factory function, so that it properly parses the immediate value:
return when (instr) {
"nop" -> Nop(value)
To obtain our second star, we now feed our original program to the generateAllMutations function, and execute the sequence of new, altered programs using the map function. At this point, we have another sequence, this time of the results of the programs.
Because we’re only interested in the first one where the instruction pointer went outside of the instructions of our program, we use the first function with a predicate that expresses exactly that. This is also the so-called terminal operation of our chain of sequences. It turns a value from our sequence into the actual MachineState as returned by the execute function.
In a way, we have actually benefited from the fact that we just built a basic simulator first without caring too much about the detection of endless loops. Because we assumed that some programs might terminate, we handled that “happy path” correctly from the beginning. That just made it easier to get our second star by running our main function once more and submitting the last state of the machine before it terminates!
Performance considerations
Before we rest on our laurels, we can revisit our code a little more and talk about the implicit decisions that we made. One of the key factors that comes to mind with our implementation is its trade-off between immutability vs performance.
Maybe without realizing it, we’ve adopted an approach for defining and executing instructions that creates a lot of objects. Specifically, each time the action associated with an Instruction is invoked, a new MachineState object is created. This approach has pros and cons:
Generally speaking, using immutability like this can make it much easier to reason about your system. You don’t need to worry that somewhere, some code will change the internal state of the objects that you are referencing. While that may not apply here, it can become a really big deal, especially if your program uses concurrency (coroutines or threads). So it’s worth considering an approach like this from the get-go.
However, we’re also paying a price by allocating so many objects. For a small simulation like the one we have here, this approach is still possible, even when the task requires us to run like 600 modified programs. But if you’re writing a simulator for a real retro gaming device, or just any machine that can store more than a few numbers, this approach isn’t really applicable. Imagine having to copy the whole content of your machine’s RAM every time your CPU executes an instruction – you can probably see why that wouldn’t work.
One opinion on the topic that’s certainly worth reading is that of Kotlin Team Lead Roman Elizarov. He actually published an article called “Immutability we can afford”, where he talks about this. If you’re conscientious about how you’re architecting and optimizing your software, you might find this a compelling read.
A mutable implementation
To get a better understanding of the difference between an immutable and a mutable implementation, we can write a second version of the simulator, allowing us to examine some very basic performance characteristics.
Instead of completely rewriting the whole project, we can introduce a new executeMutably function with the same signature as our original execute function. The key difference in its implementation is the way the instruction pointer and accumulator are stored as mutable variables. This implementation also uses a when statement instead of relying on the action associated with an Instruction, which would always allocate a new MachineState:
fun executeMutably(instructions: List<Instruction>): MachineState {
var ip: Int = 0
var acc: Int = 0
val encounteredIndices = mutableSetOf<Int>()
while(ip in instructions.indices) {
when(val nextInstr = instructions[ip]) {
is Acc -> { ip++; acc += nextInstr.value }
is Jmp -> ip += nextInstr.value
is Nop -> ip++
}
if(ip in encounteredIndices) return MachineState(ip, acc)
encounteredIndices += ip
}
return MachineState(ip, acc)
}
From an outside perspective, this function behaves exactly like the original execute function. We can validate this by adding calls to it to our main function. We can also wrap these function calls in invocations of measureTimedValue. This is an experimental function in the Kotlin standard library that can measure how long it takes for the block that it is passed to execute, and also return the original return value of that block:
The measurements that we can obtain using this of course have obvious flaws: we only run the process once, and don’t take into account things like JVM warmup time and other factors that might influence the performance of our code. While both implementations terminate within a pretty reasonable timeframe, we are indeed paying a price when we use the version which makes heavy use of immutability:
If we wanted to perform more detailed and reliable measurements, we would be better off using a framework like kotlinx.benchmark. However, even these basic numbers can give us an idea of the magnitude in performance difference between the two implementations.
At the end of the day, performance considerations like this will ultimately be up to you. Programming is a game of trade-offs, and choosing one of these implementations is another one of them.
Wrapping up
In today’s issue, we’ve gone through a lot of thinking, coding, and problem solving! Let’s quickly recap what we saw today:
We saw how we can use sealed classes and lambdas to represent the instructions of our simulated device, making sure the compiler always looks over our shoulder and ensures that we handle all instructions correctly, even when creating alternative versions of our input program.
We built a basic run cycle for our simulator, making sure we modified the machine state according to the instructions we received. We used Kotlin sets to discover loops in the execution of those input programs.
We used sequences and the sequence builder function to construct a lazy collection of programs for our second challenge. We also saw how we would yield those sequence elements on demand.
Lastly, we took some performance metrics into consideration, evaluating a different approach for executing the program and doing some armchair benchmarking using the experimental measureTimedValue function.
Many of these topics are worth diving a little deeper into, and we’re also planning on covering many of them in future videos on our official channel. So, subscribe to our YouTube channel and hit the bell to receive notifications when we continue the Kotlin journey!
As usual, we’d like to say thanks to the folks behind Advent of Code, specifically Eric Wastl, who gave us permission to use the Advent of Code problem statements for this series. Check out adventofcode.com, and continue puzzling on your own.
Let’s describe our task briefly. We are airport luggage throwers handlers, and as often happens, there are some new regulations. This time, they stipulate that all bags be color-coded and contain a specific number of color-coded bags inside them. Weird, right? Well, rules are rules, so we must comply. Let’s see what they look like:
Our mission is to find how many bags eventually contain at least one shiny gold bag.
It would be hard to find potential container bags for our shiny gold bag by hand, but programming will help us! To solve this task, we will implement a couple of search algorithms.
Part 1
We will work with a tree of bags. Trees are a good way to represent structures where things are contained in other things. The most straightforward representation of the tree in our case will be a Map of Colors to Rules, where the key is a color or the contained bag and the rule is a set of colors of bags that potentially can contain our bag.
Let’s define a couple of type aliases for that.
typealias Color = String
typealias Rule = Set<String>
We also know that the most important bag for us is the shiny gold bag. Let’s put that into a constant.
private const val SHINY_GOLD = "shiny gold"
And now, let’s define the function that will return our tree of rules.
fun main() {
val rules: Map<Color, Rule> = buildBagTree()
}
Now it’s time to start the first part of the solution: file parsing. Looking at our file again, we see each line is structured in the same way, including:
The name of the container bag
The word “bags”
The word “contain”
A single-digit number representing how many bags it contains
A comma-separated list of bags that the container bag contains
To process all the lines, we’ll remove all of the words “bags” or “bag”, all of the dots, and then the word “contain” from our string. Now, everything to the left of “contain” will be the container bag’s name and color, and everything to the right of “contain” will be the name of contained bags. In this part of the puzzle, we don’t need the numbers that the rules mention, so let’s remove them too.
We’ll use regular expressions to remove these unnecessary parts. The regular expression for deleting single digits is simple, but the one for removing “bag” and “bags” with the following dot is a bit more complex:
private fun buildBagTree(): Map<Color, Rule> {
File("src/day07/input.txt")
.forEachLine { line ->
line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
}
TODO()
}
After the pruning is complete, we need to split the string at “contain” and trim each resulting string.
private fun buildBagTree(): Map<Color, Rule> {
File("src/day07/input.txt")
.forEachLine { line ->
line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
}
TODO()
}
Let’s put the computation result into two different variables with a destructuring declaration:
private fun buildBagTree(): Map<Color, Rule> {
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
}
TODO()
}
The parent variable will contain the first element of the array, and allChildren will contain the second element of the array. Both will be strings.
Now, we need to convert the allChildren string into separate elements. We split it at the comma and trim again for each child.
private fun buildBagTree(): Map<Color, Rule> {
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
}
val childrenColors = allChildren.split(',').map { it.trim() }.toSet()
TODO()
}
Our function needs to return a tree, so let’s define one:
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
val childrenColors = allChildren.split(',').map { it.trim() }.toSet()
}
TODO()
}
Now, for each child found, we’ll check whether there is already a rule for it. If there is one, we add one more parent to it, and if not, we create a new rule. Remember that the rule is just a typealias to the set of strings.
A special function on maps called compute allows us to calculate the next value for any given key. Let’s make use of it. Note that this function is JVM-specific, so if you’re using a different platform you’ll need to use something else, like an if expression.
In our case, the key is the color of the child. The compute function accepts two arguments: the first is a key we are looking for, and the second is a lambda that, in turn, takes two arguments, our key and the current value.
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
val childrenColors = allChildren.split(',').map { it.trim() }.toSet()
for (childColor in childrenColors) {
rules.compute(childColor) { key, value ->
TODO()
}
}
}
TODO()
}
The key type is String, and the value type is Set<String>?. Now we should define separate logics for the situation when the current value is null and when the current value is not null. When the rule is null, we create a new rule and return it as a new value. If the value is not null, we add a new parent to the existing rule.
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
val childrenColors = allChildren.split(',').map { it.trim() }.toSet()
for (childColor in childrenColors) {
rules.compute(childColor) { key, value ->
if (current == null) setOf(parent)
else current + parent
}
}
}
TODO()
}
The rule is represented with an immutable set, so we can use the plus operator, which will create a new set for us. value and key aren’t very meaningful names, so let’s rename them. It also looks like the key is not used at all here because we already know our key. Let’s replace it with a special underscore value so it won’t be underlined as unused. Parsing is finished, so let’s make this function return our rules:
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
val childrenColors = allChildren.split(',').map { it.trim() }.toSet()
for (childColor in childrenColors) {
rules.compute(childColor) { _, current ->
if (current == null) setOf(parent)
else current + parent
}
}
}
return rules
}
The next part is the actual search. How do we do that? Let’s use a depth-first search, a good algorithm for traversing trees or graphs.
For each iteration, we’ll define for which bags we need to find potential parents. The first step is to define our known bags, which is currently the “shiny gold” bag (result will be stored in the known variable). In the second step, we will find potential containers found on the first iteration (for the ”shiny gold” we know that there are at least some), et cetera, et cetera, until we finish the search. The result of an iteration will be called next.
If all of the next bags are already known, then we’ll break the cycle.
Otherwise, we’ll redefine our already known bags and the next step with new values. The most exciting part here is defining the new step. It will be the potential containers of each bag in the current toFind set. For each item in the toFind set, we’ll find its containers in rules, and then flatten the search results and convert them to a set to remove any duplicates.
fun findContainersDFS(rules: Map<Color, Rule>): Set<Color> {
var known = setOf(SHINY_GOLD)
var next = setOf(SHINY_GOLD) + rules[SHINY_GOLD]!!
while (true) {
val toFind = next - known
if (toFind.isEmpty()) break
known = known + next
next = toFind.mapNotNull { rules[it] }.flatten().toSet()
}
return known - SHINY_GOLD
}
It looks like our iterative search is finished. Let’s return the results from our search function and output the final result – the known bags without the shiny gold bag itself.
fun main() {
val rules: Map<Color, Rule> = buildBagTree()
val containers = findContainersDFS(rules)
println(containers)
println()
println(containers.size)
}
I run the program and my output is 274. It’s the correct answer for how many bags contain at least one shiny gold bag.
Now let’s move on to the second part of the puzzle.
Part 2
This time the input (the list of rules) is the same, but we need to count how many bags our shiny gold bag will eventually contain.
We’ll perform the same calculation, but this time we’ll go down the tree and use the numbers (which we threw out last time) in order to count how many bags each bag will contain, and we’ll do this recursively.
Let’s look at our input again. Rereading the rules gives us new information: some bags won’t contain other bags, according to lines such as “shiny green bags contain no other bags“. That would be the end of the recursion for that kind of bag.
Now we’re going to build the same tree, but the color of the container will be the key, and the info about children will be the rule. Let’s implement the parsing logic:
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
}
return rules
}
Now let’s compute our rule for the current parent. If there is a phrase “no other” in the “allChildren” variable, the rule will be empty. Otherwise, it will contain children split by comma, trimmed, and converted into a set.
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
val rule =
if (allChildren.contains("no other")) emptySet()
else allChildren.split(',').map { it.trim() }.toSet()
rules[parent] = rule
}
return rules
}
Now we need to count the children inside the shiny gold bag with the help of a breadth-first search. A breadth-first search is an algorithm for searching a tree data structure for a node that satisfies a given property. It starts at the tree root and explores all nodes at the present depth before moving on to the nodes of the next level.
Let’s create a function for it – an extension function for our map for the sake of readability. As a parameter, it will accept the color of the bag children which we are counting.
private fun Map<Color, Rule>.getChildrenCountBFS(color: Color): Int {
TODO()
}
Remember how we kept the number of every child in the bag? Now let’s create a regular expression, which we’ll use to find the numbers in each child.
val digits = "\d+".toRegex()
We extract all children from the current bag at each level of iteration. If there are no other bags in it, we return zero.
private fun Map<Color, Rule>.getChildrenCountBFS(color: Color): Int {
val children = getOrDefault(color, setOf())
if (children.isEmpty()) return 0
TODO()
}
Now we declare the counter and start counting bags inside each child. First, we extract the count of this child in the parent bag to the variable “count”.
Second, we replace this count with nothing in the child’s name and trim the resulting name. We add to the total count and multiply by the number of bags inside each bag. On each level of recursion, we return the total after the loop:
private fun Map<Color, Rule>.getChildrenCountBFS(color: Color): Int {
val children = getOrDefault(color, setOf())
if (children.isEmpty()) return 0
var total = 0
for (child in children) {
val count = digits.findAll(child).first().value.toInt()
val bag = digits.replace(child, "").trim()
total += count + count * getChildrenCountBFS(bag)
}
return total
}
That’s it: the result is 158,730 and it’s correct!
This is what we learned about today:
How to use regular expressions
JVM-specific compute methods that allow us to dynamically calculate the value in the map based on the current value