Join us for an exciting livestream event broadcast directly from the ICPC World Finals: Kotlin Heroes Blind Coding Challenge. This is going to be a very special event featuring world-level competitive programmers: Gennady “tourist” Korotkevich, Andrew “ecnerwala” He, Pavel “pashka” Mavrin, and Egor “Egor” Kulikov.
Save the date: April 16, 2024, at 10:00 am CET.
JetBrains is a proud sponsor of the 46th and 47th ICPC World Finals, set to take place in Luxor, Egypt. As part of this event, we’re excited to showcase the incredible capabilities of Kotlin in algorithmic problem-solving.
See the talent of top-tier competitive programmers as they tackle Kotlin challenges in a unique blind coding challenge format. They’ll showcase the art of problem-solving under pressure and the power of Kotlin in action in a format where one participant has only a keyboard, and the other has only a monitor. It’s an unparalleled test of skill and adaptability!
Participants
Gennady ‘tourist’ Korotkevich
Renowned as the most decorated sports coder in the world, Gennady has dominated competitions like the Facebook Hacker Cup, Google Code Jam, and ICPC World Finals.
Andrew ‘ecnerwala’ He
A distinguished competitive programmer with numerous accolades in competitions like the Facebook Hacker Cup, Google Code Jam, and more.
Pavel ‘pashka’ Mavrin
An ICPC World Champion, Pavel brings years of experience and academic expertise to the table.
Egor ‘Egor’ Kulikov
A Google Code Jam and TopCoder Open champion, Egor is a force to be reckoned with in the world of competitive programming.
We have two consecutive presentations lined up, each featuring a thrilling blind programming challenge and insightful commentary from JetBrains Developer Advocate Garth Gilmour.
Don’t miss this opportunity to witness top programmers in action and discover the power of Kotlin in competitive coding. Mark your calendars and join us on April 16 for an unforgettable experience!
Prepare for technical interviews and hone your algorithm skills during our special event ‘Mastering Algorithmic Problem Solving: Insights From Kotlin Heroes’ featuring two ICPC World Champions, the most significant award in algorithmic problem-solving.
Meet our expert presenters:
Pavel Mavrin is a tutor and researcher at JetBrains, renowned for his expertise in algorithms and data structures. Pavel won the ICPC World Champion title in 2004. Watch his Parallel Algorithms lecture.
Pavel Kunyavskiy is an ICPC 2014 champion and Technical Lead in Kotlin Common Backend at JetBrains. With his vast experience in judging and participating in programming competitions, Pavel is here to share his invaluable insights.
During the ‘Mastering Algorithmic Problem Solving: Insights From Kotlin Heroes’ livestream, they’ll tackle problems from our last competition, Kotlin Heroes: Episode 9. Hosted by JetBrains and Codeforces, Kotlin Heroes contests are perfect for honing your programming skills, whether you’re a seasoned programmer or new to programming.
Date: Apr 9, 2024
Time: 6:00 pm CET
Join us for an engaging session packed with problem-solving strategies, tips, and more!
The upcoming IntelliJ IDEA 2024.1 comes with an optional K2 mode. In this mode the IDE uses the K2 compiler for faster and more robust Kotlin code analysis. The IDE now has two modes:
Classic mode (enabled by default) – the IDE uses the standard (K1) Kotlin compiler to analyze Kotlin code.
K2 mode (now in Alpha) – the IDE uses the new K2 compiler as its code analysis engine.
These modes affect only code analysis in the IDE. If you want to compile your project with the K2 compiler, you will need to specify this in the project’s build settings. The K2 IDE mode does not depend on the Kotlin compiler version specified in the project’s build settings.
What is the K2 mode?
We rewrote the Kotlin compiler from scratch to improve performance and enhance internal architecture, facilitating further development of the Kotlin language. Furthermore, as the Kotlin compiler is used as a code analysis engine in the IDE, the K2 compiler is optimized to meet the requirements of the IDE.
The K2 mode provides:
Compatibility with future Kotlin features: The new mode will support future language features that will only be provided in the K2 Kotlin compiler.
Code analysis stability: We expect code analysis to be more stable, which will mean no more Highlighting is suspended due to internal error messages! Thanks to the colossal architecture redesign, the quality and reliability of the IDE features should improve.
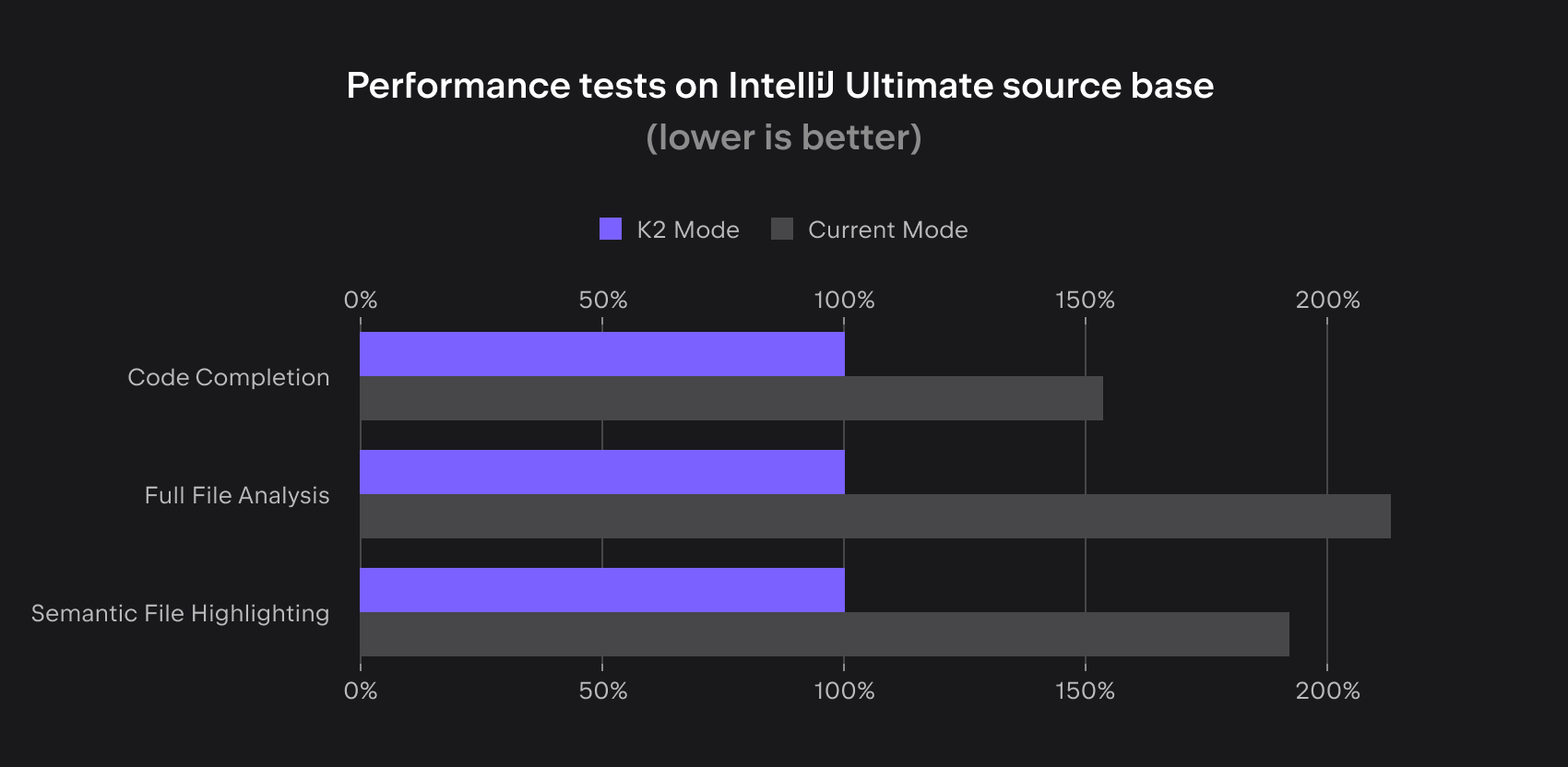
Better IDE performance: The speed of Kotlin code highlighting and Kotlin code completion has been significantly increased.
Performance tests on IntelliJ Ultimate source base
Improved API: In subsequent versions, we’re planning to introduce a resilient and easy-to-use API for third-party plugins.
What IDE features are supported?
To provide support for the K2 compiler in IntelliJ IDEA, we wrote from scratch many IDE features as they strongly rely on the K1 compiler’s API. It allowed us to rethink the current design and solve problems that can’t be addressed in the K1-based IDE configuration.
We’re not rushing to implement or migrate as many IDE features as possible. We aim to perfect a smaller number of features each time, ensuring the best quality. We will steadily enrich IDE feature support with each subsequent release, hopefully with the benefit of your feedback.
Basic editing features, such as code formatting, parameter info, gutter icons, QuickDoc, the import optimizer, and Type Hierarchy.
Some of the most popular inspections, intentions, and quick-fixes.
New project wizards, project importing, and running tests and applications from IntelliJ IDEA.
In IntelliJ IDEA 2024.1, K2 mode does not support:
Kotlin Multiplatform projects (KMP).
Android projects.
The Extract Function refactoring.
Inlay hints.
Java-to-Kotlin conversion.
Methods and Calls Hierarchy.
Smart Step Into.
Tools for debugging coroutines.
Code analysis in .gradle.kts files.
Other minor features.
Third-party IntelliJ IDEA plugins depending on the Kotlin plugin will be disabled. We will provide migration guidance for third-party plugin authors soon!
Support for missing features will be added in the upcoming releases.
How to try the K2 Kotlin compiler mode?
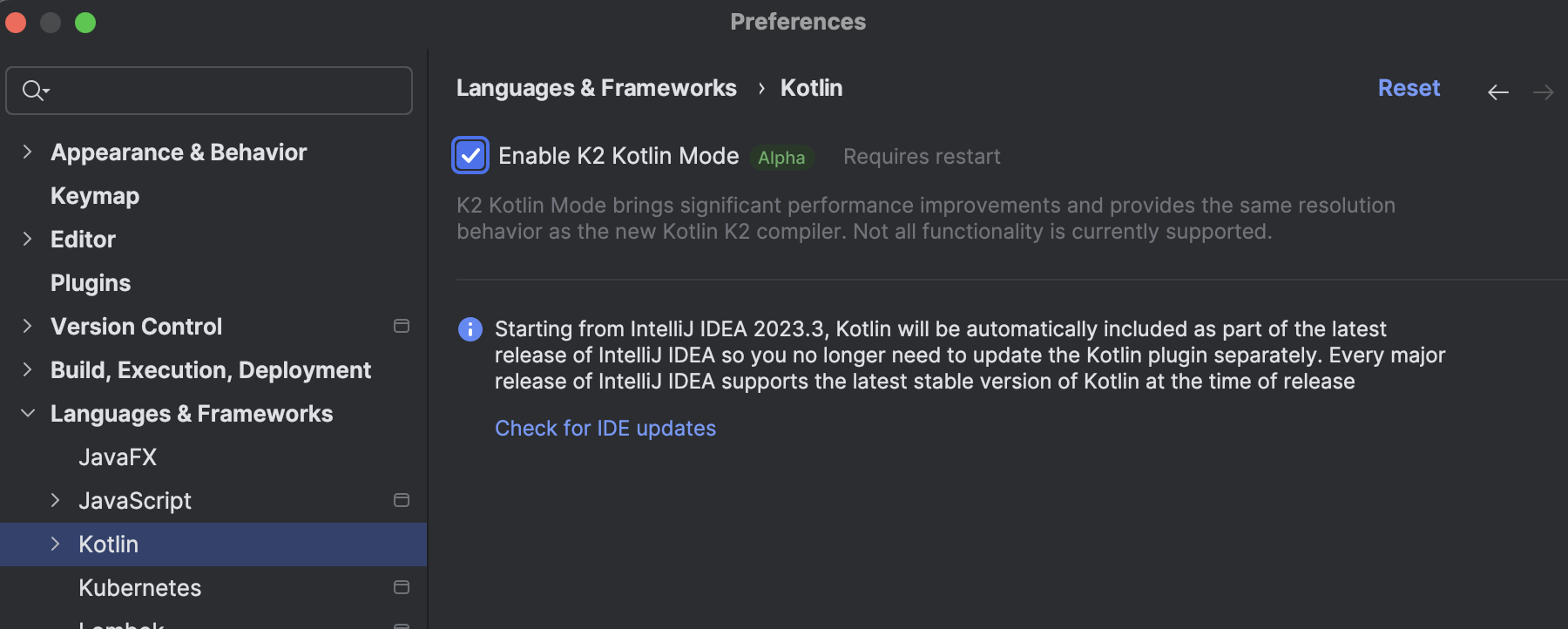
Go to Settings | Languages & Frameworks | Kotlin, and click the Enable the K2-based Kotlin plugin checkbox to enable the new mode.
After switching on the K2 mode, you will need to restart the IDE.
Feedback
We welcome your feedback and would love to hear about your experience with IntelliJ IDEA’s K2 Kotlin mode, the features you want us to bring to this mode, and your thoughts about its performance.
Please share your experience with us by leaving a comment below, messaging us in our public Slack channel, or creating an issue in YouTrack.
We are actively working to improve this functionality, and your feedback will help us!
The JetBrains team has released the latest version of Compose Multiplatform, a modern declarative UI framework that allows developers to share UIs across different platforms. The 1.6.0 version revamps the resource management library, introduces a UI testing API, adds iOS accessibility support, and brings the common @Preview annotation supported by JetBrains Fleet.
With the 0.2.0 release of Amper, an experimental project configuration tool by JetBrains, we have some exciting feature updates to share. Amper now supports Gradle version catalogs, including code completion, navigation between declarations and usages, and intention actions to move dependencies to catalogs. To make it easier to find dependencies and their versions, you will now get completion for dependencies when editing an Amper manifest, powered by Package Search.
We aim to keep Ktor a lightweight, flexible, and transparent framework so our users can easily create powerful and maintainable services and clients. With each new release, we try to improve the quality and performance of features while simultaneously expanding our ecosystem of Ktor plugins. If you want to learn more about our plans and goals for Ktor, explore our roadmap for 2024.
Configuration Language Survey – help shape the future of build configurations
We’re exploring the potential of a new configuration language to streamline project build setups. If you’ve ever configured a build for your projects, we need your input. Take our survey and help shape the future of build tooling!
Become a Kotlin Google Summer of Code contributor and make an impact!
The Kotlin Foundation has been accepted as a mentor organization for Google Summer of Code 2024. GSoC is a global online program focused on bringing new contributors into open-source software development. If you are a student or a beginner, GSoC offers an opportunity to work on meaningful projects and connect with mentors from the Kotlin community. Join us for GSoC 2024 to gain real-world development experience and improve your technical skills!
Last December, we shared daily Advent of Code in Kotlin livestreams of puzzle solutions, presented by our host Sebastian Aigner and his fantastic guests. If you missed any of the action, you can watch the recordings on our YouTube playlist. Dive into Kotlin discussions and gain a wealth of knowledge.
If you’re struggling with anxiety and doubt when giving a conference talk, watch the recording of our Strategies of Successful Conference Talks livestream. Garth Gilmour, a Developer Advocate at JetBrains, has been organizing and presenting at conferences for over 20 years. In this livestream, he shares his top tips for success and discusses how to be prepared for whatever life throws at you on the big day.
Kotlin Notebooks is an environment where you can write and execute code fragments and create beautiful interactive tables displaying hierarchical data, which makes it a good place for prototyping and trying out ideas. In this livestream, you’ll learn how to use Kotlin Notebooks for data analysis, see how Notebooks parses and visualizes complex data, and get a sneak peek into the potential of the Dataframe and Kandy libraries.
Learn to refactor using your IDE for better Kotlin code
Get ready to uncover the secrets hidden within your code with our new course, Introduction to IDE Code Refactoring in Kotlin. Whether you’re a novice or an intermediate programmer, this course will give you the skills to use your IDE to improve the design and structure of your code making it more readable, maintainable, and robust.
The Kotlin Foundation has been accepted as a mentor organization for Google Summer of Code 2024!
GSoC is a global online program focused on bringing new contributors into open-source software development. Contributors work on a 12-week programming project under the guidance of Kotlin Foundation mentors from Google, Gradle, and JetBrains.
What does this mean for you?
As a potential contributor, this is your chance to explore open-source development with Kotlin. If you are a student or a beginner, GSoC offers an opportunity to work on meaningful projects, gain hands-on experience, and connect with mentors from the Kotlin community.
Why participate?
By joining us for GSoC 2024, you’ll have the chance to:
Gain real-world development experience and enhance technical skills.
Contribute to a real Kotlin project with a global impact and play a part in expanding the Kotlin ecosystem.
Learn from experienced mentors and connect with the Kotlin community.
Receive a stipend and build your resume.
How do I get started?
Explore the exciting projects we have lined up and check out our GSoC guidelines.
A big thank you goes out to everyone who joined us for Advent of Code in Kotlin this year! We’re thrilled that JetBrains was a part of this yearly tradition once again as one of the Advent of Code sponsors.
From December 1 through 12, we shared daily livestreams of puzzle solutions presented by our host Sebastian Aigner and his fantastic guests. If you missed any of the action, you can watch the recordings on our YouTube playlist. Dive into Kotlin discussions, learn something new, and enjoy the good vibes:
This year, we again threw the challenge to the community, inviting you all to solve puzzles using Kotlin – and the response was phenomenal!
Here’s a quick recap:
1,400 repositories were labeled with the “aoc-2023-in-kotlin” topic and were therefore included in the challenge.
We featured a total of 12 guests on our 12 daily livestreams.
We invited everyone to join one of our leaderboards and start solving the Advent of Code puzzles in Kotlin. Now, we’d like to take a moment to congratulate our 15 standout winners, who will soon be receiving some exclusive prizes!
Here are the top five performers from the combined Kotlin leaderboards, which had a total of 1,320 participants:
A massive round of applause to all our participants and winners, and a special thank you to Eric Wastl and the entire Advent of Code organizational team!
We hope you had fun, and we’re looking forward to seeing you all for the next edition of Advent of Code in Kotlin! Meanwhile, check out the following links and keep exploring the language:
Catch up on the highlights of what happened in the Kotlin ecosystem in December and January!
Kotlin for WebAssembly goes Alpha
Kotlin/Wasm, the newest Kotlin Multiplatform target platform, has reached Alpha status! This means that Kotlin/Wasm is ready for you to use in pre-production scenarios. It still has many areas that are works in progress, and we continue to rely on the community to help inform and prioritize the decisions influencing Kotlin/Wasm.
Additionally, Compose Multiplatform for the web (currently experimental) leverages Kotlin/Wasm. Together, the two technologies enable developers to create declarative user interfaces for web applications entirely in Kotlin.
Don’t miss out on the world’s largest Kotlin event. Anticipate exciting keynote speeches, sessions, and workshops presented by industry experts and passionate Kotlin enthusiasts. Participants will have the opportunity to explore the most recent developments, adopt best practices, and learn from success stories. Join us at Copenhagen’s beautiful Bella Center on May 22–24!
If you’re planning to attend KotlinConf this year, you might be interested in our Hands-On Kotlin Web Development with Ktor workshop. In this full-day workshop, Anton Arhipov, Developer Advocate at JetBrains, and Leonid Stashevsky, Team Lead for Ktor at JetBrains, will show you how to create a feature-complete application using Ktor, Exposed, and various Kotlin and Java libraries. For more details, check out the official KotlinConf 2024 website.
KotlinConf Global 2024: uniting Kotlin enthusiasts worldwide!
KotlinConf Global is a series of meetups organized by the community to watch and discuss the keynote addresses and sessions at the conference. Become part of KotlinConf 2024 by hosting your own event!
Kandy: the new Kotlin plotting library by JetBrains
In December, the JetBrains team introduced Kandy, a new Kotlin plotting library. Boasting a user-friendly DSL, Kandy seamlessly integrates with Kotlin DataFrame and Kotlin Notebook, offering a cohesive approach to effortless chart creation.
How to migrate an Android project to Kotlin Multiplatform (video)
Do you want to learn about how to migrate an Android project to Kotlin Multiplatform? Then, be sure to watch this deep-dive video tutorial by Philpp Lackner. In this session, Philipp walks you through the process of taking your existing native Android project in Android Studio and migrating it to Kotlin Multiplatform, so that you can use the app on iOS as well.
Amper Update: highlights of user feedback and our plans
Amper is a new tool by JetBrains to improve the project configuration user experience. Since its release last November, we’ve received a lot of feedback from the community and have continued our development work as well. Check out some of the highlights of what we’ve heard from you and a little about where we’re headed next in our blog post.
2023 marked Kotlin’s first-ever participation in Google Summer of Code (GSoC), a global online program focused on bringing new contributors into open-source development. Contributors worked on 12-week programming projects with the Kotlin Foundation under the guidance of mentors from JetBrains, Google, and Gradle.
Here is the final list of projects that we worked on last summer, along with reviews from mentors and contributors:
2023 marked Kotlin’s first-ever participation in Google Summer of Code (GSoC), a global online program focused on bringing new contributors into open-source development. Contributors worked on 12-week programming projects with the Kotlin Foundation under the guidance of mentors from JetBrains, Google, and Gradle, and gained experience on real-world projects. We would like to share the results achieved during GSoC 2023.
Improve support for parameter forwarding in the Kotlin plugin for IntelliJ IDEA
Enhance the kotlinx-benchmark library API and user experience
Parallel stacks for Kotlin Coroutines in the debugger
We received 65 high-quality proposals from potential contributors.
After careful evaluation, mentors and organization admins selected the top 5 contributors to work on projects that promised to make a significant impact on the Kotlin community. Halfway through the program, one of the selected contributors withdrew from the “Improve support for parameter forwarding in the Kotlin plugin for IntelliJ IDEA” project, so the final list shrank to 4 projects.
Here is the final list of projects that we worked on last summer, along with reviews from mentors and contributors:
We’re grateful to everyone who participated in Google Summer of Code with the Kotlin Foundation. We are determined to make participating in GSoC a tradition.
Thank you for being a part of this journey with us!
KotlinConf Global returns next year, in May. This means that no matter where you are in the world, you can join us in celebrating all things Kotlin.
At KotlinConf 2024, you can expect a great lineup of keynotes, sessions, and workshops, delivered by industry experts and Kotlin enthusiasts. The attendees will be able to deep dive into the latest updates, best practices, and success stories.
Whether you’re a Kotlin developer, a team lead, or simply someone passionate about Kotlin, you’re sure to find something of interest to you. As we bring the global Kotlin community together, you’ll have the chance to network, collaborate, and forge new connections that can inspire you and elevate your work.
We encourage communities, companies, and campuses around the world to become part of KotlinConf 2024 by hosting their own events. By organizing a live broadcast of the conference with your local Kotlin community, you can recreate the excitement of being physically present at the event. Not only that, but you’ll also gain access to video recordings, allowing you to hold watch parties at a later date and enjoy the KotlinConf experience.
To ensure your event is a success, our team is ready to provide support every step of the way. If you require guidance or have any questions about organizing your KotlinConf Global event, reach out to us at kug@jetbrains.com. We’re here to help make your event an unforgettable one.
To get support for your event, you should host it between May 23, 2024, and June 30, 2024. Make sure to announce it on your website or another suitable platform, such as meetup.com. The closing date for submissions is February 23, 2024.
Attend an Event
For those who can’t organize an event but still want to be part of the excitement, fear not. Stay tuned to our website and follow @kotlinconf on X (formerly Twitter) for updates on upcoming events.
As we bring the global Kotlin community together, you’ll have the chance to network, collaborate, and forge new connections that can inspire you and elevate your work.
Kotlin/Wasm, the newest Kotlin Multiplatform target platform, has reached Alpha status! Here’s what you need to know about this change at a glance:
JetBrains has promoted Kotlin/Wasm to Alpha, making it ready for you to try for yourself. Your feedback will help shape the future of building web applications with Kotlin!
As an Alpha release, Kotlin/Wasm is ready for you to use in pre-production scenarios, but it still has many areas that are works in progress. We rely on the community to help inform and prioritize the decisions influencing Kotlin/Wasm.
Compose for Web (currently experimental) is powered by Kotlin/Wasm. Together, the two technologies allow you to create declarative user interfaces for web applications in 100% Kotlin.
WebAssembly: The newest Kotlin Multiplatform target
WebAssembly is establishing itself as the standard compilation target for languages targeting the browser – and beyond! With Kotlin/Wasm, we’re giving you the ability to make use of this new target via Kotlin Multiplatform. We first introduced Kotlin/Wasm in Kotlin 1.8.20 as an experimental technology, and have since improved and refined it.
Because Kotlin is an automatically memory-managed language, it builds on the garbage collection proposal, which recently reached phase 4 (standardization). That means it is now enabled by default in a number of major browsers. For example, recent versions of both Chrome and Firefox can run Kotlin/Wasm applications without any required adjustments. While Safari currently doesn’t support Wasm GC yet, implementation of the required functionality in JavaScriptCore is already underway.
An easy way to get started with Kotlin/Wasm is to take a look at the Getting Started page. Here, you’ll find an overview of the technology and instructions on how to set up your own Kotlin/Wasm application. You’ll also see projects and links to example projects that show off different facets of Kotlin/Wasm, including those that illustrate how to use it in the browser, together with Compose Multiplatform, and more.
The Kotlin Playground now also has support for Kotlin/Wasm, meaning you can write your first WebAssembly code snippets right in your browser, and explore what Kotlin/Wasm has to offer.
Ktor, the JetBrains framework for building networked applications, is also coming to WebAssembly. With the next release, you’ll be able to use Ktor’s HTTP clients to make network requests right from your Kotlin/Wasm code.
Compose Multiplatform: Powered by Kotlin/Wasm
Kotlin/Wasm isn’t bound to any specific UI framework. It’s a general way of running your Kotlin code in the browser. However, it is the underlying technology for the experimental web target of Compose Multiplatform, the declarative multiplatform UI toolkit by JetBrains based on Google’s Jetpack Compose. Compose Multiplatform for Web uses canvas-based rendering, meaning that you can use the same layouts and components as you would on other platforms. Out of the box, it comes with the Material and Material 3 design components.
With Compose Multiplatform, you can build shared applications that target the most important platforms: Android and iOS, desktop, and – thanks to the power of Kotlin/Wasm – the browser. To start building your own shared UIs, you can generate a project using the Kotlin Multiplatform Web Wizard, which now also experimentally supports the Kotlin/Wasm target.
Performance
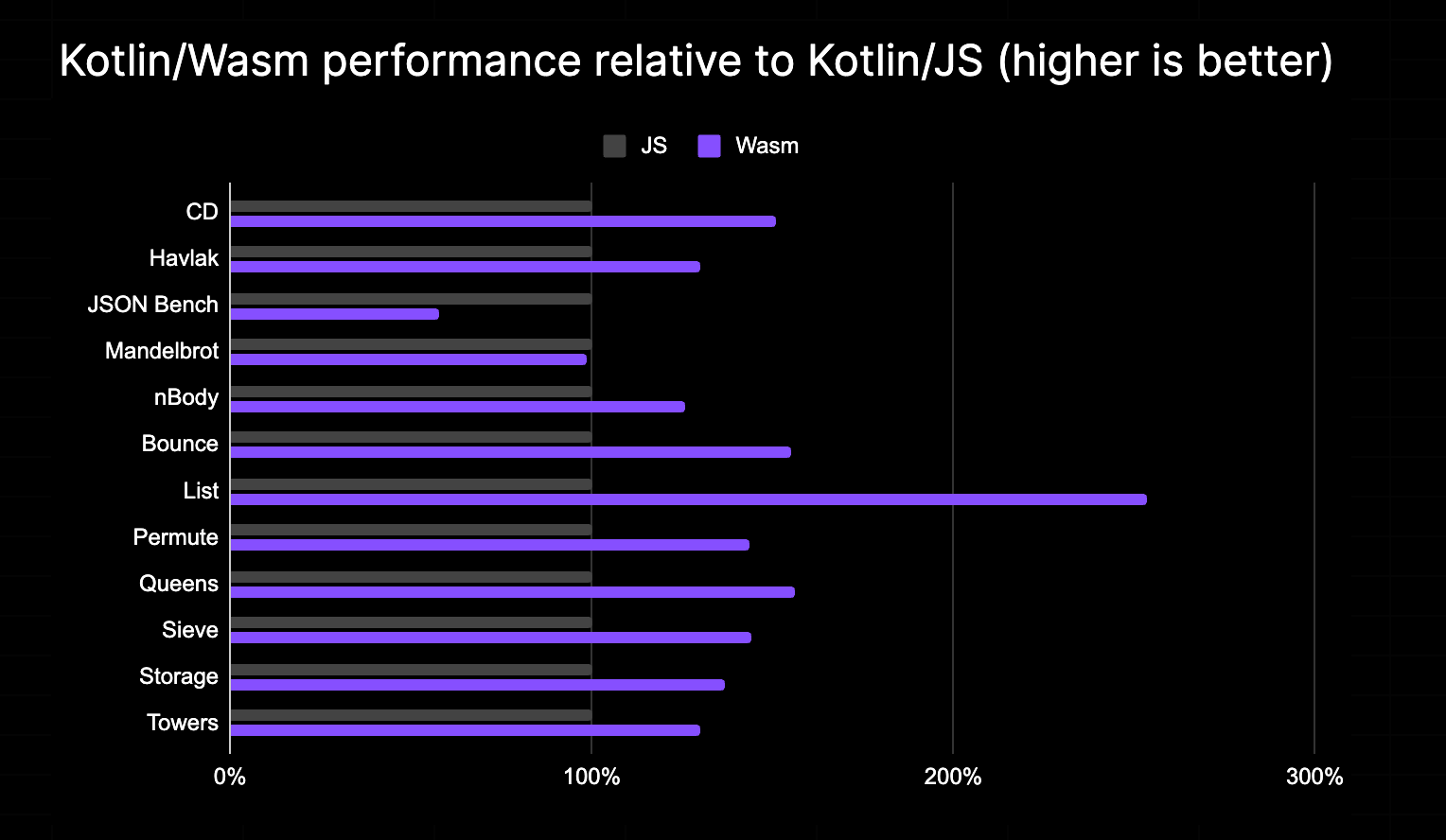
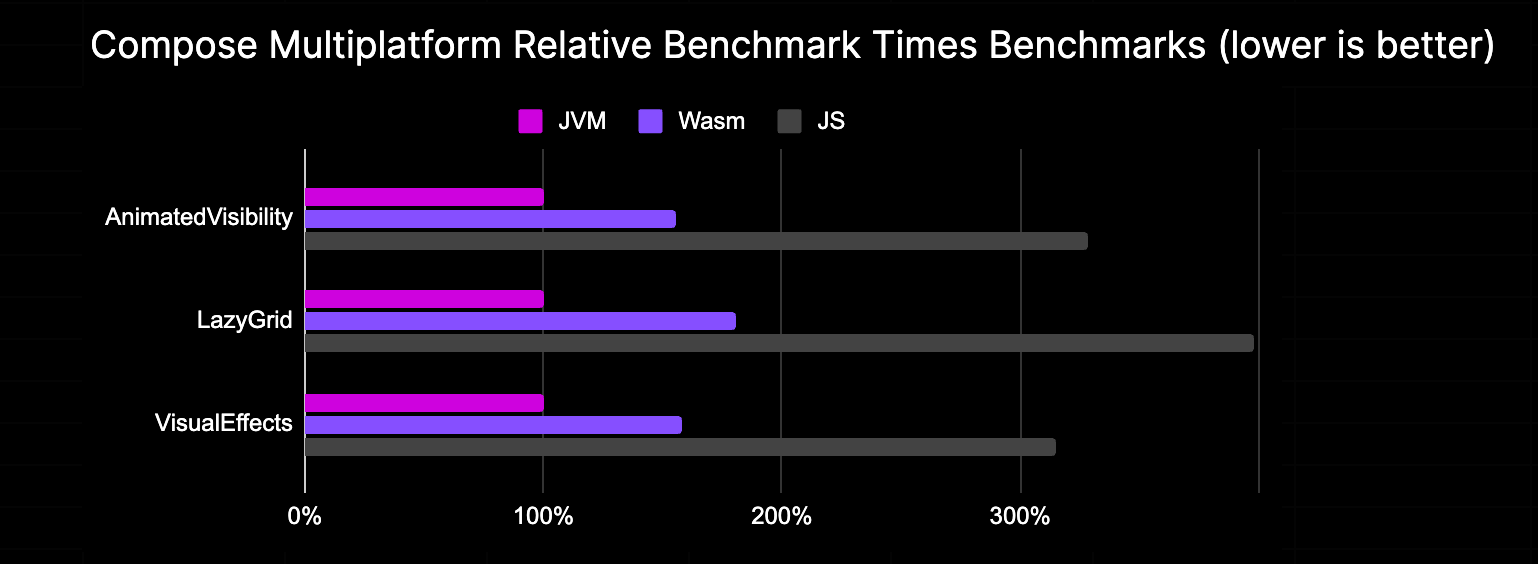
WebAssembly is designed from the ground up as a compilation target for languages, meaning the Kotlin compiler can convert your source code into performant WebAssembly bytecode. We regularly run benchmarks on Kotlin/Wasm to ensure its runtime performance. Since Kotlin/Wasm is still in Alpha, the team continues to work on performance improvements, but as you can see, Kotlin/Wasm already outperforms Kotlin/JS in almost all of our macro benchmarks:
Likewise, Compose Multiplatform running on Kotlin/Wasm already shows promising performance characteristics, with execution speed comparable to that of running the same application on the JVM:
These benchmark results come from our testing in a recent version of Google Chrome, but we observed similar results in other browsers we tested.
What’s in the works
As a technology in Alpha, Kotlin/Wasm is evolving rapidly, and the team is busy making improvements and enhancements. As such, there are still a number of areas that are works in progress.
Currently, the debugging support in Kotlin/Wasm is limited, and we’re working on improving its capabilities going forward. We’re also aware that bundle size is an important factor when it comes to targeting the web, and we want to further optimize the outputs generated by the compiler, especially for Compose Multiplatform projects.
As WebAssembly continues evolving, we want to take advantage of new proposals as they arrive – whether that’s stack switching, threading, or others. We’re also working on introducing support for the WebAssembly Component Model to Kotlin, which will enable you to build interoperable Wasm libraries and applications. We’re also still in the process of making Kotlin/Wasm an awesome target for development outside of the browser, including support for WASI, the WebAssembly System Interface. As a part of the WebAssembly Community Group, and by actively collaborating with vendors of WebAssembly VMs, we’re striving to ensure that Kotlin/Wasm provides a great experience no matter where you’re running it.
Our goal is to provide an excellent developer experience for you, and make sure that it meets your requirements in terms of performance and bundle size. As we make progress on these fronts, we’ll make sure to provide you with updates and share more information!
Join the community to get updates and share your feedback!
If you want to connect with the team and other developers excited about Kotlin/Wasm, we invite you to join the discussion on the Kotlin Slack (get your invite here). In the #webassembly channel, you can find discussions about everything Kotlin and WebAssembly.
Kotlin/Wasm is in Alpha, and we want to make sure we continue evolving the technology based on your requirements. Help us help you by reporting problems, telling us about APIs that you feel are missing, and requesting features you’d like to see. You can do so by adding issues to the Kotlin YouTrack project.
We’re excited to take this next step with Kotlin and look forward to seeing what you’ll create with Kotlin/Wasm!
See Kotlin/Wasm in action!
On Tuesday, December 12, 2023, Kotlin/Wasm Team Lead Zalim Bashorov will present a live session entitled Kotlin and WebAssembly: Unleashing Cross-Platform Power on the official Kotlin YouTube channel! To make sure you don’t miss it, sign up to receive notifications.
November has been a busy and eventful month with a lot of exciting news and many updates in the Kotlin Multiplatform ecosystem. Catch up on all the highlights in our digest.
Kotlin Developer Survey
We want to hear from Kotlin developers! Help us make Kotlin even better by completing this 10-minute survey and sharing your opinions about the language, libraries, IDEs, and build tools. By participating, you will also get the chance to win a one-year JetBrains All Products Pack subscription or a $100 Amazon Gift Card.
Kotlin Multiplatform is Stable and production-ready
Kotlin Multiplatform (KMP) is an open-source technology built by JetBrains that allows developers to share code across platforms while retaining the benefits of native programming. KMP is now Stable and 100% ready for you to use in production. Read our blog post to learn about the evolution of the framework, how it can streamline your development process, and what educational resources are available for you to get the most out of the technology.
The JetBrains team has launched a preview for Kotlin Multiplatform support in Fleet, which simplifies the development of multiplatform applications, adding to the already extensive Kotlin support in Fleet. Its features include:
Simplicity: Run configurations for Android and/or iOS are generated automatically.
Polyglot programming: You don’t have to switch to a different editor when working with native code in your multiplatform project.
Amper – Improving your build tooling user experience
Amper is a new experimental project configuration tool focused on usability, onboarding, and IDE support. To sum it up, here’s a brief overview of all there is to know about this tool so far:
You can currently use Amper with Kotlin and Kotlin Multiplatform, though it also supports Java and Swift.
Implemented as a Gradle plugin, Amper uses YAML for its project configuration format.
Compose Multiplatform 1.5.10 – The perfect time to get started
Compose Multiplatform is a declarative UI framework built by JetBrains that allows developers to share their applications’ UIs across different platforms. The 1.5.10 release of Compose Multiplatform provides support for Kotlin 1.9.20 and offers the following features:
Quicker and easier startup
New Material 3 components in common code
Enhanced TextFields on iOS
Crossfade animation for UIKit interoperability
Increased compilation speed
Basic support for the K2 compiler
Enhanced rendering performance on iOS
A new documentation portal
For more details about 1.5.10, read our blog post. Compose Multiplatform 1.5.11 is now also available, providing compatibility with Kotlin 1.9.21 and several fixes to ensure a more stable and reliable framework.
The JetBrains team is adding many awesome things to Kotlin Multiplatform to provide you with the best cross-platform development experience. Our plans for 2024 include:
Direct Kotlin-to-Swift export
Compose for iOS in Beta
A single IDE experience with Fleet
Improved KMP library publishing process
Delve into our updated roadmap to see what’s cooking.
If you missed our educational livestreams, the recordings are now available to watch online. Enjoy the Kotlin Multiplatform Webinar November series to get insights directly from JetBrains experts!
Tackle Advent of Code 2023 with Kotlin and win prizes!
Advent of Code is a great way to discover new Kotlin features, enhance your problem-solving skills, and engage with a fantastic community. Dive into 25 days of coding challenges at adventofcode.com for some friendly competition, valuable learning experiences, and the chance to win exclusive Kotlin prizes!
Unwrap the joy of coding challenges as we gear up for Advent of Code, which JetBrains is proud to be sponsoring for a third consecutive year! Starting December 1, the JetBrains community will be diving into 25 days of coding challenges at adventofcode.com, and we warmly invite you to participate using Kotlin.
Advent of Code is a great way to discover new Kotlin features, enhance your problem-solving skills, and engage with a fantastic community. Take part for some friendly competition, valuable learning experiences, and the chance to win exclusive Kotlin prizes!
Starting December 1, we’ll be holding livestreams every day at 5:00 pm UTC to discuss the puzzle of the day, giving you 12 hours to solve the puzzle before we go through it together. We’ll be joined by guests from the Kotlin team and the community to discuss possible approaches to the problems. It’s a great way to tackle the challenges together and learn some cool Kotlin tricks!
Community
Join the discussion in the Advent of Code channel on the Kotlinlang Slack, and share tips and tricks with other participants. Each day we’ll post a new thread where you can share your puzzle solutions. The most active community members will get some neat rewards!
Take part in our dedicated Kotlin leaderboards. We’ll randomly pick several winners from among those who submit their solutions on GitHub, and the top scorers will also get some fantastic prizes.
Since the leaderboard space is limited and in high demand, we’ve created seven leaderboards to fit everyone interested. To join, head to the Leaderboard section in your Advent of Code profile and enter one of the codes below:
Leaderboard 1: 2553782-b2a92b30
Leaderboard 2: 3240090-7d776460
Leaderboard 3: 3240094-c8ce397b
Leaderboard 4: 3240651-e9dd79d4
Leaderboard 5: 3240655-edd1d88b
Please join only one leaderboard. Thank you!
Resources
We’ve compiled some useful Advent of Code resources to help you get in the spirit:
Make the most of our GitHub template, which is designed to streamline the structure of your solutions. This repository template is specifically for use with Kotlin, and it offers a solid foundation for your solutions, allowing you to get set up quickly so you can dive right into the problems.
To create a new project with this template, simply log in to your GitHub account, follow the link below, and click the green Use this template button. Please do not fork it!
This is a fork of the main Advent of Code Kotlin Template repository that uses the Amper tool for project configuration, recently introduced by JetBrains. With this version, we swapped the standard Gradle build configuration with the module.yaml Amper file.
Prizes
For a chance to grab some fantastic prizes by participating in Advent of Code with Kotlin, be sure to follow these steps:
Tackle at least three days of Advent of Code 2023 challenges in Kotlin.
Share your solutions publicly on GitHub.
Have your contact details (email address or Twitter handle) available in your GitHub profile.
Follow the Advent of Code guidelines, which forbid you from using AI or LLMs to solve the puzzles.
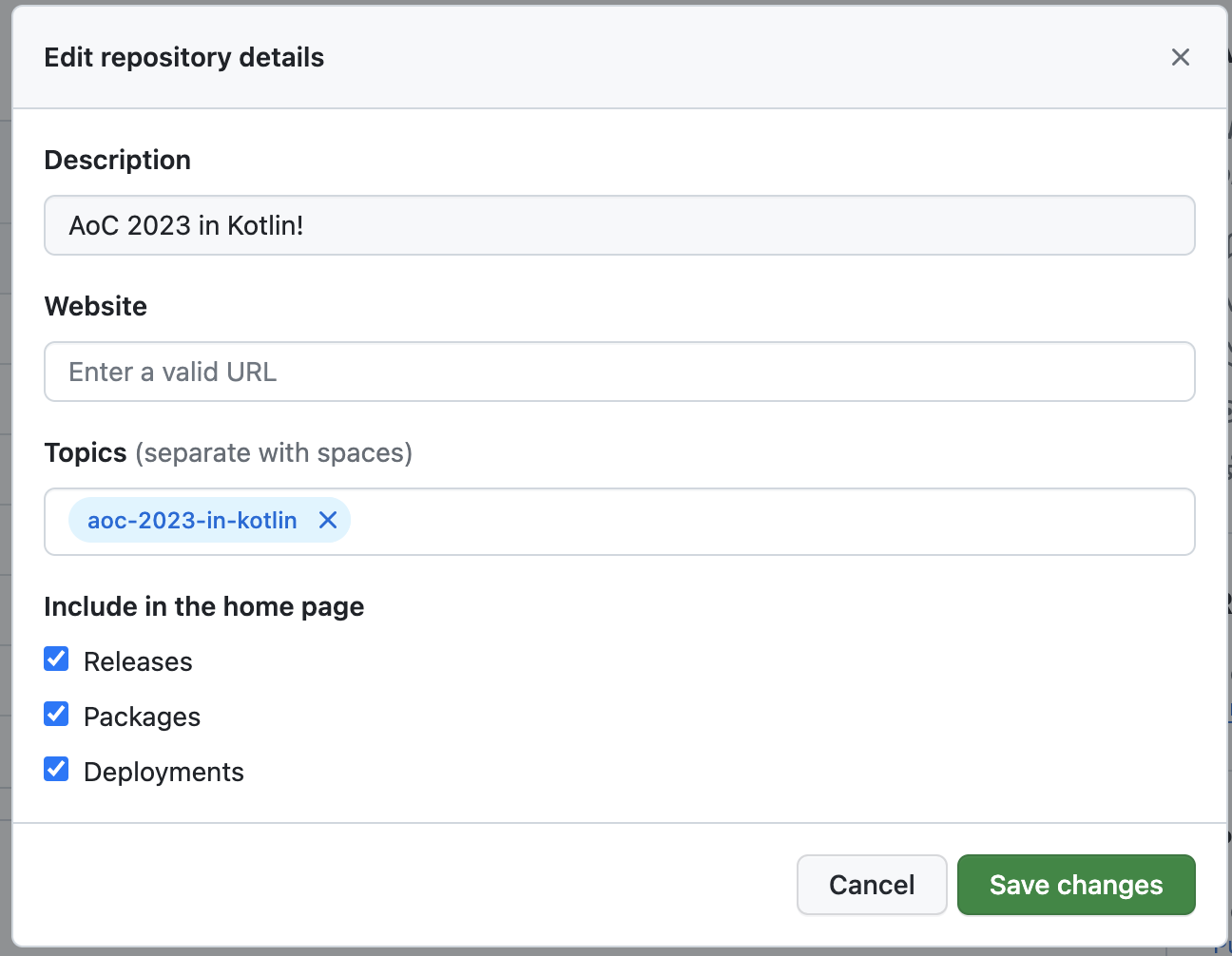
Add the topic “aoc-2023-in-kotlin” to your repository.
To include the “aoc-2023-in-kotlin” topic in your repository, edit the repository details by clicking the gear icon in the top right-hand corner of the repository page. Next, in the topics field, add the value:
We genuinely appreciate everyone’s enthusiasm for this friendly competition! Our aim is to provide you with an enjoyable experience as you explore the beauty of solving holiday puzzles in idiomatic Kotlin.
Join us for Advent of Code 2023 with Kotlin for a chance to learn, have fun, and be a part of a fantastic community!