import java.io.File
fun main() {
val numbers = File("src/day1/input.txt")
.readLines()
.map(String::toInt)
}
将此代码放入 main 函数中,该函数是程序的入口点。 当您开始输入时,IntelliJ IDEA 会自动导入 java.io.File。
现在,我们只需迭代列表,然后对每个数字重复该迭代并检查和:
for (first in numbers) {
for (second in numbers) {
if (first + second == 2020) {
println(first * second)
return
}
}
}
将此代码放在 main 中,这样一来,找到所需数字时, return 会从 main 返回。
以类似的方式检查三个数字的和:
for (first in numbers) {
for (second in numbers) {
for (third in numbers) {
if (first + second + third == 2020) {
println(first * second * third)
return
}
}
}
}
val pair = numbers.mapNotNull { number ->
val complement = complements[number]
if (complement != null) Pair(number, complement) else null
}.firstOrNull()
fun List<Int>.findPairOfSum(sum: Int): Pair<Int, Int>? {
// Map: sum - x -> x
val complements = associateBy { sum - it }
return firstNotNullOfOrNull { number ->
val complement = complements[number]
if (complement != null) Pair(number, complement) else null
}
}
Advent Of Code is currently ongoing and many people all over the world are taking part. We’d like to share some tips and tricks for solving the puzzles in Kotlin – we hope you find some of them helpful! Feel free to add your favorite tips or thoughts in the comments!.
If you’re solving the puzzles in Kotlin, don’t forget to add the aoc-2021-in-kotlin topic to your repo to take part in our giveaway! If you’re starting from scratch, consider using our prepared Github template.
How do you usually go about solving the puzzles? First of all, you read and parse the input data. Let’s start with some tips for this process, and then discuss tips for writing the actual solutions in Kotlin.
1. Jumping between sample and real input
All of the Advent of Code puzzles provide your own “personal” input and the sample input to check your solution. You often need to switch back and forth between the sample and real input. If the solution for the first part works for the sample input, you then need to run it on the real input to get your result. If the solution then works on the real input, you likely switch back to the sample input to start solving the second part of the puzzle.
One of the ways to switch between two inputs quickly is by using comments with the IntelliJ IDEA action “Comment with Line Comment”. This changes the line state and removes the comment from the commented line, rather than simply adding a comment.
You can put the sample and real inputs in different files and toggle between comments for the file names by pressing the Ctrl+/ shortcut twice:
These small things make a difference and make working with IntelliJ IDEA a pleasure!
2. Parsing input
The next thing to do after reading the input is to parse it. You can either use the Kotlin library functions for working with strings or regular expressions. Library functions like substringBefore() and substringAfter() cover lots of cases and are often enough. Use String.toInt() and Char.digitToInt() to convert the string content or characters into integers.
For more complicated scenarios, there are regular expressions. Use the destructured function to assign the output to different variables right away:
val inputLineRegex = """(d+),(d+) -> (d+),(d+)""".toRegex()
val (startX, startY, endX, endY) = inputLineRegex
.matchEntire(s)
?.destructured
?: throw IllegalArgumentException("Incorrect input line $s")
The action “Check RegExp” in IntelliJ IDEA allows you to quickly check whether the sample input satisfies your regular expression.
3. Storing input
It’s often helpful to introduce domain types, even for smaller tasks like these puzzles. Solving the task for Cells and Boards, or for Segments and SevenSegmentDigits can be much easier than working directly with Ints, List of Lists of Ints, or Chars and Sets of Chars. Types help to direct your thinking to the heart of the problem.
Kotlin makes this really easy – define a one-line data class and that’s it. You don’t need a separate file, like in Java, since it’s in your main file with the rest of your solution code:
data class Step(val direction: Direction, val units: Int)
In Kotlin, you can use an extension to convert an input line directly to a required type:
fun String.toStep(): Step
fun String.toTicket(): Ticket
fun String.toSevenSegmentDigitList(): List<SevenSegmentDigit>
Then your typical starter code will look like this:
val steps = readInput(fileName).map(String::toStep)
You can either use the function reference String::toStep or the lambda expression map { it.toStep() }.
4. Enumerations instead of strings
It might be tempting to manipulate the string literals directly, but making them enum constants makes it easier to write the code and reason about how it works. You never know what comes in the second part of the puzzle!
enum class Direction { UP, DOWN, FORWARD }
data class Step(val direction: Direction, val units: Int)
It is easy to convert an input string to an enum and use the EnumClassName.valueOf("") function to get the constant by name:
With when expressions you can check all of the options and you don’t need to include the else branch:
IntelliJ IDEA can generate all the branches automatically.
for ((direction, units) in steps) {
when (direction) {
UP -> depth -= units
DOWN -> depth += units
FORWARD -> horizontalPosition += units
}
}
Note that in the destructuring declaration syntax in the for loop, you automatically assign two properties, the contents of each Step, into two loop variables.
5. From typealias to a class
If working with primitives is easier at first, and defining a separate class looks too cumbersome, consider defining a typealias. You can convert it into a class later, if needed. When you replace a typealias with a class, most of the code continues to compile, and you immediately see which functions are missing.
typealias Segment = Char
data class SevenSegmentDigit(val segments: Set<Segment>) {
constructor(s: String): this(s.toSet())
override fun toString() = segments.toList().sorted().joinToString("")
}
For example, the characters from 'a' to 'g' used to encode the seven-segment display can be referred to as Segments in the code and be regular Chars underneath. You can define the SevenSegmentDigit class first as a typealias for Set and later convert it to a class, for example, if you want to replace a default toString with a custom one.
6. Building lists and maps
In addition to the standard listOf(), mutableListOf(), and similar functions, you can use other methods to build collections.
You can call the List function that looks like a constructor (but is not!) to provide a way to calculate each element:
List(4) { it * it } // [0, 1, 4, 9]
Use buildList and buildMap functions to build data structures imperatively:
val monsters: List<Position> = buildList {
for (y in 0..tile.size - Monster.height) {
for (x in 0..tile.size - Monster.width) {
if (monsterAt(tileRotation, x, y)) {
add(Position(x, y))
}
}
}
}
In this example, we call add on a MutableList inside the lambda, and the resulting type is the read-only List.
The similar sequence {..} function builds a Sequence lazily yielding values one by one.
7. Associate and group
The task of building a map from a list occurs quite often, and associate and groupBy functions make this operation straightforward. You can group elements by the provided property with groupBy, use elements as map keys to provide a way to build values (associateWith), use elements as values (associateBy), or provide a way to build a key-value pair from each element (associate).
The groupBy function groups the elements with the specified value used as a map key:
The result of calling countSegmentInAllDigits in this example becomes the key in the map.
If you don’t need the groups directly, but you need to find the size of each group, use a lazy counterpart to groupBy: the groupingBy function. It doesn’t return a map straightaway, but it allows you to analyze the groups in a lazy manner:
If the property you’re using to group the elements is unique, use associateBy. For instance, if you need to access elements by their indexes, associateBy will build a map from indexes to elements for you:
val rulesMap: Map<Int, Rule> = rules.associateBy { it.index }
Let’s imagine you need to build a map representing an initial state by associating each of the input numbers with the corresponding Node. Use associateWith:
val initialState: Map<Int, Node> = numbers.associateWith { Node(it) }
If you need more complicated keys and values, use associate:
val bagRuleMap: Map<Bag, List<Content>> = bagRules.associate { it.bag to it.contentList }
If you don’t remember which associate function you need, choose the general associate one, and IntelliJ IDEA will suggest a better one automatically:
numbers.windowed(2).count { (first, second) -> first < second }
"abcde".windowed(2) // [ab, bc, cd, de]
An alternative to building a list of chunks of size 2 is to use zipWithNext().
9. Sum of, min of
You don’t need to map the elements first to later find the resulting sum – the sumOf function combines these two operations. IntelliJ IDEA even suggests these replacements automatically:
There are similar functions maxOf and minOf for finding the maximum and minimum among the transformed values.
10. Adding index
Need to perform computations with an element index? In addition to the withIndex() extension that returns a list of pairs to iterate through, you can use many “indexed” counterparts for standard library functions, such as forEachIndexed, filterIndexed, mapIndexed, foldIndexed, and so on.
In the following example, the final calculateScore function uses the indexed version of fold to include an index into a computation of the result:
fun RoundConfiguration.calculateScore(): Long {
val winner = listOf(playerA, playerB).maxByOrNull { it.size }!!
return winner
.cards()
.foldIndexed(0L) { index, acc, element ->
acc + (winner.size - index) * element
}
}
Note how we marked 0 as a Long constant here (0L) to perform the computation on Long values.
11. Also logging
If the puzzle answer isn’t correct and you want to track the intermediate results step by step, you can print or log the intermediate values. The also function allows you to include println or log directives in the middle of the call chain or display the function result if you use an expression-body syntax.
In this example, we return the result of the function and also do some logging:
private fun checkRow(row: List<Int>, visited: Set<Int>) =
row.all { elem -> elem in visited }
.also { result -> log("Checking row $row $visited: $result") }
Here, we insert also calls in the middle of the call chain to observe the intermediate results of the computation:
val differences = input
.windowed(2)
.also(::log)
.map { (first, second) -> second - first }
.also(::log)
.sorted()
If you need to print each list element on a separate line, you can include .onEach(::println) to the middle of the call chain. onEach performs an operation on each element and returns the unmodified list.
To avoid commenting on the lines with println, make a habit of using your own small log function instead. This way, you only need to change it in one place to stop printing all of the intermediate values for your solution.
12. Queue and stack together
Need a queue or a stack to implement an algorithm when solving the puzzle? Use ArrayDeque, a double-ended queue that provides quick access to both ends. It can be used either as a queue or a stack when needed.
For instance, in a classic implementation of a depth-first search, create a queue as an ArrayDeque and call its add and removeFirst methods inside:
fun dfs(board: Board, initial: Cell): Set<Cell> {
val visited = mutableSetOf<Cell>()
val queue = ArrayDeque<Cell>()
queue += initial
while (queue.isNotEmpty()) {
val cell = queue.removeFirst()
visited += cell
queue += board.getUpperNeighbors(cell)
}
return visited
}
In this example, we use the short syntax += to call the plusAssign(element: T) and plusAssign(elements: Iterable) operators, which simply redirect to the corresponding add functions.
Of course, the ArrayDeque structure is useful any time you need quick access to both the start and end of the list of elements.
13. Operators
Operator overloading, which looks like mostly library or DSL-magic functionality, might also be useful when solving such small puzzles.
Consider overloading get and set operators to simplify the code for working with your class. For instance, by providing the get operator that takes Cell as an argument for the following class you can access its content more easily:
Instead of writing board.content[cell.i][cell.j] for all invocations, you write
board[cell]. You can provide the set operator for mutable content accordingly.
Using the contains operator might make the code cleaner:
data class Line(val start: Point, val end: Point) {
operator fun contains(point: Point): Boolean { … }
}
Then you can call it via the in keyword:
inputLines.count { line -> point in line }
If your elements are comparable, you can make them implement the Comparable interface, and then compare the elements using the standard <, <=, >, and >= operations.
———
Last but not least, consider creating a collection of your utilities specifically for solving Advent of Code puzzles. For example, you’ll definitely find a task that requires a point with two integer coordinates and uses its neighboring points!
That’s all for now! We hope that you enjoy solving the AdventOfCode puzzles as much as we do, and find these small tips useful!
The nautical advent-ure continues with the third day of AOC 2021, which we will, of course, once more solve in Kotlin! This time, it will involve wrangling binary numbers in all sorts of ways. Check out the solution and a detailed explanation on YouTube, or follow along as we explain our solution in this blog post!
Solving part 1
We’re on maintenance duty today: That means we’re working with a report of binary numbers. Our goal is to calculate two values in order to get our gold star. They are referred to as the gamma and epsilon rate in the original problem description, which you can find on adventofcode.com.
We calculate the gamma rate by determining the most common bit for each position of the binary numbers in our input. When there’s more “1” bits than “0” bits in a column, the resulting number will be a “1”. Or when it is the other way around, and we see more “0” bits than “1” bits, our result will have a “0” in that position. We repeat that process for each column in our inputs until we get the final gamma rate in binary representation.
The epsilon rate is calculated analogously to the gamma rate, only this time, it always looks at the least common bit in each position.
Once both numbers are calculated, we arrive at the answer – the power consumption of our submarine – by converting the two numbers to decimal, and multiplying them.
Let’s turn our intuitive understanding into a Kotlin program! These examples use the scaffolding provided by the Advent of Code Kotlin Template, but a standalone solution would look very similar.
fun main() {
fun part1(input: List<String>): Int {
TODO()
}
val testInput = readInput("Day03_test")
val input = readInput("Day03")
println("P1 Test: " + part1(testInput))
check(part1(testInput) == 198)
println("P1 Result: " + part1(input))
}
Gamma rate: Most popular bits
From the problem description, we know that we are going to need to iterate our list of inputs (a list of binary strings) column by column. We can assume that all numbers in the input have the same length, so we can use the zero’th element, and save its indices into a variable via the indices function.
We can then loop over all the column indices, and count the number of ones and zeroes in that column to help us decide what we should do next. Ideally, we would like to use a function such as the following:
val columns = input[0].indices
for(column in columns) {
input.countBitsInColumn(column)
}
Since this is a pretty problem-specific function, the standard library does not come with an implementation for it. But with the power of extension functions, we can build this exact function ourselves! A simple implementation looks like this:
private fun List<String>.countBitsInColumn(column: Int): Pair<Int, Int> {
var zeroes = 0
var ones = 0
for(line in this) {
if(line[column] == '0') zeroes++ else ones++
}
return zeroes to ones
}
The function keeps track of the ones and zeroes, and returns them as a Pair (constructed via the infix function to).
We can still make this code a bit more expressive, by replacing the Pair return type with our own custom data class:
private data class BitCount(val zeroes: Int, val ones: Int)
By having the function return an instance of BitCount, the zeroes and ones can be accessed explicitly, and our code has become a little bit more expressive:
val bitCount = input.countBitsInColumn(column)
val zeroes = bitCount.zeroes
val ones = bitCount.ones
Since BitCount is a data class, we can use a destructuring declaration to elegantly access the zeroes and ones directly instead of having to write the three lines above. This single line has the same effect:
val (zeroes, ones) = input.countBitsInColumn(column)
Creating the string of binary numbers that makes up the gamma rate is now a matter of figuring out which bit is more popular, and concatenating all of these bits into a single string. To do so, we can use Kotlin’s buildString function, which gives us access to a StringBuilder. We can combine that with a short if-expression, and append the most common bit to the gammaRate string:
val gammaRate = buildString {
for (column in columns) {
val (zeroes, ones) = input.countBitsInColumn(column)
val commonBit = if (zeroes > ones) "0" else "1"
append(commonBit)
}
}
This makes up the first half of the solution for part 1. To see the calculated value, we can turn this string of binary digits back into a real integer using the toInt function, and telling it we’re looking at a base-2 number:
return gammaRate.toInt(2)
This outputs “22”! We can confirm that this is indeed the correct gamma rate for the given sample input by going back to adventofcode.com and carefully re-reading the instructions. Great!
Epsilon rate: The binary inverse
Moving on to the epsilon rate, we make use of the property we observed in our initial discussion: the epsilon rate is just the binary inverse of the gamma rate. Where you see a “1” in the gamma rate, there’s a “0” in the epsilon rate, and vice versa. Once again, using an extension function, the call site for the epsilon rate looks like this:
val epsilonRate = gammaRate.invertBinaryString()
We can use a few primitives from the standard library to assemble the implementation for invertBinaryString: we use the asIterable function to get access to the individual characters, and use the joinToString function to turn each “0” into a “1” and each “1” into a “0”:
private fun String.invertBinaryString() = this
.asIterable()
.joinToString("") { if (it == '0') "1" else "0" }
To get the final result, we multiply these two numbers together, and obtain the power consumption of the submarine, which we can submit and get our first gold star for the day!
return gammaRate.toInt(2) * epsilonRate.toInt(2)
Intermission: An alternative approach for the gamma rate
Before moving on to part 2 of the challenge, let’s reuse our knowledge that joinToString takes a transform function, and attempt to write a more functional version of the algorithm that calculates the gamma rate in this problem. We can combine the map function, a destructuring declaration, and joinToString to get the same result as the solution that uses a for-loop, buildString, and append:
Having seen both solutions, which one do you prefer? Feel free to let us know in the comments below, or on our YouTube video!
Here’s the complete implementation of part 1 again, for reference:
fun part1(input: List<String>): Int {
val columns = input[0].indices
val gammaRate = buildString {
for (column in columns) {
val (zeroes, ones) = input.countBitsInColumn(column)
val commonBit = if (zeroes > ones) "0" else "1"
append(commonBit)
}
}
val gammaRate2 = columns
.map { input.countBitsInColumn(it) }
.joinToString("") { (zeroes, ones) ->
if (zeroes > ones) "0" else "1"
}
check(gammaRate == gammaRate2)
val epsilonRate = gammaRate.invertBinaryString()
return gammaRate.toInt(2) * epsilonRate.toInt(2)
}
private fun String.invertBinaryString() = this
.asIterable()
.joinToString("") { if (it == '0') "1" else "0" }
private fun List<String>.countBitsInColumn(column: Int): BitCount {
var zeroes = 0
var ones = 0
for (line in this) {
if (line[column] == '0') zeroes++ else ones++
}
return BitCount(zeroes, ones)
}
Solving part 2
For part 2, we once again multiply numbers together: this time, the oxygen generator rating, and the CO2 scrubber rating! You can find detailed instructions on how to calculate these numbers on adventofcode.com. We’ll also discuss the computation of the oxygen generator rating here as an example.
The algorithm once again iterates the numbers column by column again, determining the most frequent bit (or, in the case of the CO2 scrubber rating, the least frequent bit). Then, the process of elimination is applied: all numbers that don’t have the most frequent bit are removed, and only the numbers which have the most popular bit in the given position remain. Tiebreakers go to the numbers with “1” in a given position for the oxygen generator rating, and the inverse for the CO2 scrubber.
This process is repeated until only one number remains, which is our result.
Computing the oxygen generator rating
Let’s start by defining a small local function for it, and let’s fill in some logic. We can structure the function similarly to our solution for part 1. To implement the process of elimination, we need to keep track of all the candidate numbers (starting with all of the input). We then need to repeatedly filter the list to make sure only the numbers with the most common bit at any given position remain.
We can reuse our countBitsInColumn implementation to arrive at a solution that looks like this:
fun oxyRating(): String {
val columns = input[0].indices
var candidates = input
for(column in columns) {
val (zeroes, ones) = candidates.countBitsInColumn(column)
val mostCommon = if (zeroes > ones) '0' else '1'
candidates = candidates.filter { it[column] == mostCommon }
if(candidates.size == 1) break
}
return candidates.single()
}
When coming up with this snippet, it’s important we take great care to ensure the if-condition handles tiebreakers correctly: If “0” and “1” are equally common, it keeps values with a “1” in the position being considered.
Because I made the choice to use an immutable list here, removing elements is done via the filter function, which creates a new list. This list can then be assigned to the candidates variable again. If you’d like, you can also try to use a mutable list, and use the removeIf function for this algorithm, instead.
The only candidate that should remain can be extracted from the collection via the single function, and then returned. This allows us to already check our first partial result:
return oxyRating().toInt(2)
Copy-pasting the CO2 implementation
We can get our quick-and-dirty implementation of the CO2 scrubber rating by copy-pasting the code we wrote a moment ago, and adjusting the filter condition to keep only those candidates that don’t have the most common bit:
fun co2Rating(): String {
val columns = input[0].indices
var candidates = input
for (column in columns) {
val (zeroes, ones) = candidates.countBitsInColumn(column)
val mostCommon = if (zeroes > ones) '0' else '1'
candidates = candidates.filter { it[column] != mostCommon }
if(candidates.size == 1) break
}
return candidates.single()
}
Together with our previous partial solution, this is actually enough to get our second gold star for the day – multiply the numbers, run the program, and get your reward:
Hopefully, you’ll agree at this point that our code could still be improved before we check it into our repository. Both co2Rating and oxyRating are essentially the same function, just with a different parameter. We only changed a single line of code in them – why would we want to have all that other code lying around as well? We can do better. We can define an enum class RatingType to distinguish between the types of ratings we want to calculate:
private enum class RatingType {
OXYGEN,
CO2
}
We can then turn one of the two rating functions into a multi-purpose implementation by using a when-statement based on the requested RatingType:
fun part2(input: List<String>): Int {
fun rating(type: RatingType): String {
val columns = input[0].indices
var candidates = input
for (column in columns) {
val (zeroes, ones) = candidates.countBitsInColumn(column)
val mostCommon = if (zeroes > ones) '0' else '1'
candidates = candidates.filter {
when (type) {
RatingType.OXYGEN -> it[column] == mostCommon
RatingType.CO2 -> it[column] != mostCommon
}
}
if (candidates.size == 1) break
}
return candidates.single()
}
return rating(RatingType.OXYGEN).toInt(2) * rating(RatingType.CO2).toInt(2)
}
This code works the same, but is much more concise, and doesn’t contain duplications anymore. That’s much better!
We’re done!
That’s it! This code can go into our repository, and we can celebrate another problem solved, and hopefully some more Kotlin lessons learned.
If you’re coming up with your own solutions for Advent of Code, or if you’ve coded along to our videos, make sure to share your code on GitHub, and add the topic aoc-21-in-kotlin to your repo! This way you have a chance to win some Kotlin swag this holiday season! Check out the “Advent of Code 2021 in Kotlin” blog post for more details.
In this post, I’m going to walk you through my solution to the Advent of Code 2021 Day 1 task. Of course, I used Kotlin to solve it!
The input for the task is a text file, where each line is a number that represents a measurement of the depth of the seafloor. The task is to count the number of measurements where the depth increases. For example:
In the sample input above, there are 10 measurements. The depth of the seafloor increases 7 times, and that would be the correct answer for the task.
To read the file, I used the following line of code:
File("input.txt").readLines()
The result was a list of strings, but I actually needed a list of integers. Hence, I came up with the following helper function to read the input file and transform it into a list of integers:
fun readInputAsInts(name: String) = File("src", "$name.txt").readLines().map { it.toInt() }
Since the task is to compare each number to the previous one, I needed to read the numbers in pairs: the first and the second, then the second and the third, and so on. The Kotlin standard library provides a very useful function for this situation: windowed().
val input = readInputAsInts("Day01")
val list: List<List<Int>> = input.windowed(2)
The result was a list where each element was a pair of integers that I needed to compare and see whether the second integer was greater.
The count function with a predicate as a parameter is perfect for this situation. I was able to implement the whole solution as follows:
val input = readInputAsInts("Day01")
input.windowed(2).count { (a, b) -> a < b }
As is usually the case in Advent of Code puzzles, the requirement changes in the second part. I now needed to work with a three-measurement sliding window. For the sample input above, this meant that I needed to read three numbers (199, 200, 208), then read another triple (200, 208, 210), calculate the total for both triples, and compare them. Then I would count the number of cases where the second total was greater than the first. In this example 199+200+208 < 200+208+210, meaning this case counts.
The solution that was appealing to me was to optimize the condition for this task a bit. I needed to compare the totals of the triples as follows: 199+200+208 <=> 200+208+210. I saw the same two numbers on both sides of the equation, which meant I could just eliminate these figures, leaving me with 199 < 210.
Each pair of triplets contained a total of only four numbers, so I was able to group the input by four elements and compare the first number to the last:
input.windowed(4).count { it[0] < it[3] }
The solution to the second part of the challenge turned out to be rather simple! I have published the code for my solution to the Advent of Code GitHub repository if you’d like to compare it to yours. Have fun with Advent of Code this year!
It’s that magical time of the year! Supermarkets are stocking cookies, the smell of cinnamon and roasted chestnuts fills the air, and maybe you’ll even see some snowflakes fall in front of your window. It can only mean one thing: Advent of Code is coming!
It starts December 1, when the first of twenty-five coding puzzles is unlocked. From then on, a new coding challenge comes out each day. Whether you’re a beginner programmer or seasoned professional, there isn’t a better or cozier way to give your problem-solving skills a workout than the fun seasonal challenges from adventofcode.com.
At JetBrains, we’re proud to be supporting Advent of Code this year as one of its top sponsors. Many people across our different teams are already looking forward to solving and discussing the new challenges. To get you in the mood for AOC 2021, we’ve prepared a primer video that covers:
Basic tips on how to get up and running with solving AOC 2021 in Kotlin.
A ready-made GitHub template to give you some structure.
Some of the added incentives we have for those who try their hand at solving the challenges in Kotlin.
In addition to having fun and exchanging ideas with the community, our team is giving you an extra reason to share your code on GitHub this year! We’re giving away some Kotlin care packages to sweeten the holiday season for our community.
When we select the lucky winners, we’ll need to be able to find you and your code. So, to enter, make sure you meet the following conditions:
You have attempted to solve at least three days of AOC 2021.
You have shared your code publicly on your GitHub account.
You have added the aoc-2021-in-kotlin topic to your repository (see below).
You have a contact method (email, Twitter) on your GitHub profile.
To reiterate, you don’t need to be the fastest or complete every single challenge. Take your time, have fun, and use this opportunity to learn something new!
To add the aoc-2021-in-kotlin topic to your repository, edit the repository details by clicking the gear icon in the top right corner on the repository page. Then, in the topics field, add the value.
That’s all you need to do – with a bit of luck, we’ll reach out to you and arrange for your little surprise to be delivered to you!
GitHub template
If you want to start your Advent of Code journey with a bit of structure, you can use our GitHub repository template. It provides you with some basic scaffolding to structure your solutions and do automated testing using JUnit. To get started and receive a customized repository for your personal solutions, just press the “Use this template” button on the repository page. Do not fork the project.
You can find information about the structure of the repository, its content, and where to put your solution files in the template README.
Please note that even when using this template, you’ll have to add the aoc-2021-in-kotlin tag manually to your repository in order to participate in the giveaway.
Solve problems and have fun!
We hope you’re excited for the challenges you’ll be getting each day throughout December, and that you’ll use this opportunity to play with Kotlin and discover something new that will be useful in other contexts.
As a last piece of advice: when doing Advent of Code, take your time, have fun, learn new things, and don’t feel pressured. You might have fun competing with your friends, but the most important thing is for you to enjoy yourself while spending time with the puzzles. After all, Kotlin is meant to be fun!
Enjoy the holiday season, indulge in some treats, and solve some interesting problems with Kotlin. Happy holidays!
This post continues our “Idiomatic Kotlin” series and provides the solution for the Advent of Code Day 9* challenge. While solving it, we’ll look into different ways to manipulate lists in Kotlin.
Day 9. Encoding error, part I
We need to attack a weakness in data encrypted with the eXchange-Masking Addition System (XMAS)! The data is a list of numbers, and we need to find the first number in the list (starting from the 26th) that is not the sum of any 2 of the 25 numbers before it. We’ll call the number valid if it can be presented as a sum of two numbers from the previous sublist, and invalid otherwise. Two numbers that sum to a valid number must be different from each other.
If the first 25 numbers are 1 through 25 in a random order, the next number must be the sum of two of those numbers to be valid:
26 would be a valid next number, as it could be 1 plus 25 (or many other pairs, like 2 and 24).
49 would be a valid next number, as it is the sum of 24 and 25.
100 would not be valid; no two of the previous 25 numbers sum to 100.
50 would also not be valid; although 25 appears in the previous 25 numbers, the two numbers in the pair must be different.
Solution, part I
Let’s solve the task in Kotlin! For a start, let’s implement a function that checks whether a given list contains a pair of numbers that sum up to a given number. We’ll later use this function to check whether a given number is valid by passing this number and the list of the previous 25 numbers as arguments.
For convenience, we can define the function as an extension on a List of Long numbers. We need to iterate over all the elements in the list, looking for the two with the given sum. The first naive attempt will be using forEach (we call it on this implicit receiver, our list of numbers) to iterate through the elements twice:
fun List<Long>.hasPairOfSumV1(sum: Long): Boolean {
forEach { first ->
forEach { second ->
if (first + second == sum) return true
}
}
return false
}
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSumV1(26)) // true; 26 = 1 + 25
println(numbers.hasPairOfSumV1(49)) // true; 49 = 24 + 25
println(numbers.hasPairOfSumV1(100)) // false
// This is wrong:
println(numbers.hasPairOfSumV1(50)) // true; 50 = 25 * 2
}
But this solution is wrong! Using this approach, first and second might refer to the same element. But as we remember from the task description, two numbers that sum to a valid number must be different from each other.
To fix that, we can iterate over a list of elements with indices and make sure that the indices of two elements are different:
fun List<Long>.hasPairOfSumV2(sum: Long): Boolean {
forEachIndexed { i, first ->
forEachIndexed { j, second ->
if (i != j && first + second == sum) return true
}
}
return false
}
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSumV2(50)) // false
}
This way, if first and second both refer to 25, they have the same indices, so they are no longer interpreted as a correct pair.
We can rewrite this code and delegate the logic for finding the necessary element to Kotlin library functions. For this case, any does the job. It returns true if the list contains an element that satisfies the given condition:
//sampleStart
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
//sampleEnd
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSum(50)) // false
}
Our final version of the hasPairOfSum function uses any to iterate through indices instead of elements and checks for a pair that meets the condition. indices is an extension property on Collection that returns an integer range of collection indices, 0..size - 1; we call it on this implicit receiver, our list of numbers.
Finding an invalid number
Let’s implement a function that looks for an invalid number, one that is not the sum of two of the 25 numbers before it.
Before we start, let’s store the group size, 25, as a constant. We have a sample input that we can check our solution against which uses the group size 5 instead, so it’s much more convenient to change this constant in one place:
const val GROUP_SIZE = 25
We define the group size as const val and make it a compile-time constant, which means it’ll be replaced with the actual value at compile time. Indeed, if you use this constant (e.g. in a range GROUP_SIZE..lastIndex) and look at the bytecode, you’ll no longer be able to find the GROUP_SIZE property. Its usage will have been replaced with the constant 25.
For convenience, we can again define the findInvalidNumber function as an extension function on List. Let’s first implement it more directly, and then rewrite it using the power of standard library functions.
We use the example provided with the problem, where every number but one is the sum of two of the previous 5 numbers; the only number that does not follow this rule is 127:
//sampleStart
const val GROUP_SIZE = 5
fun List<Long>.findInvalidNumberV1(): Long? {
for (index in (GROUP_SIZE + 1)..lastIndex) {
val prevGroup = subList(index - GROUP_SIZE, index)
if (!prevGroup.hasPairOfSum(sum = this[index])) {
return this[index]
}
}
return null
}
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV1()) // 127
}
//sampleEnd
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
Because we need to find the first number in the input list that satisfies our condition starting from the 26th, we iterate over all indices starting from GROUP_SIZE + 1 up to the last index, and for each corresponding element check whether it’s invalid. prevGroup contains exactly GROUP_SIZE elements, and we run hasPairOfSum on it, providing the current element as the sum to check. If we find an invalid element, we return it.
You may think that the sublist() function creates the sublists and copies the list content, but it doesn’t! It merely creates a view. By using it, we avoid having to create many intermediate sublists!
We can rewrite this code using the firstOrNull library function. It finds the first element that satisfies the given condition. This allows us to find the index of the invalid number. Then we use let to return the element staying at the found position:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumberV2(): Long? =
((GROUP_SIZE + 1)..lastIndex)
.firstOrNull { index ->
val prevGroup = subList(index - GROUP_SIZE, index)
!prevGroup.hasPairOfSum(sum = this[index])
}
?.let { this[it] }
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV2()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
Note how we use safe access together with let to transform the index if one was found. Otherwise null is returned.
Using ‘windowed’
To improve readability, we can follow a slightly different approach. Instead of iterating over indices by hand and constructing the necessary sublists, we use a library function that does the job for us.
The Kotlin standard library has the windowed function, which returns a list or a sequence of snapshots of a window of a given size. This window “slides” along the given collection or sequence, moving by one element each step:
Here we build sublists, that is, snapshots, of size 2 and 3. To see more examples of how to use windowed and other advanced operations on collections, check out this video.
This function is perfectly suited to our challenge, as it can build sublists of the required size automatically for us. Let’s rewrite findInvalidNumber once more:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumberV3(): Long? =
windowed(GROUP_SIZE + 1)
.firstOrNull { window ->
val prevGroup = window.dropLast(1)
!prevGroup.hasPairOfSum(sum = window.last())
}
?.last()
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV3()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
To have both the previous group and the current number, we use a window with the size GROUP_SIZE + 1. The first GROUP_SIZE elements form the necessary sublist to check, while the last element is the current number. If we find a sublist that satisfies the given condition, its last element is the result.
Note about the difference between sublist and windowed functions
Note, however, that unlike sublist(), which creates a view of the existing list, the windowed() function builds all the intermediate lists. Though using it improves readability, it results in some performance drawbacks. For parts of the code that are not performance-critical, these drawbacks usually are not noticeable. On the JVM, the garbage collector is very effective at collecting such short-lived objects. It’s nevertheless useful to know about these nuanced differences between the two functions!
There’s also an overloaded version of the windowed() function that takes lambda as an argument describing how to transform each window. This version doesn’t create new sublists to pass as lambda arguments. Instead, it passes “ephemeral” sublists (somewhat similar to sublist() views) that are valid only inside the lambda. You should not store such a sublist or allow it to escape unless you’ve made a snapshot of it:
fun main() {
val list = listOf('a', 'b', 'c', 'd', 'e')
// Intermediate lists are created:
println(list.windowed(2).map { it.joinToString("") })
// Lists passed to lambda are "ephemeral",
// they are only valid inside this lambda:
println(list.windowed(2) { it.joinToString("") })
// You should make a copy of a window sublist
// to store it or pass further:
var firstWindowRef: List<Char>? = null
var firstWindowCopy: List<Char>? = null
list.windowed(2) {
if (it.first() == 'a') {
firstWindowRef = it // Don't do this!
firstWindowCopy = it.toList()
}
it.joinToString("")
}
println("Ref: $firstWindowRef") // [d, e]
println("Copy: $firstWindowCopy") // [a, b]
}
If you try to store the very first window [a, b] by copying the reference, you see that by the end of the iterations this reference contains different data, the last window. To get the first window, you need to copy the content.
A function with similar optimization might be added in the future for Sequences, see KT-48800 for details.
We can further improve our findInvalidNumber function by using sequences instead of lists. In Kotlin, Sequence provides a lazy way of computation. In the current solution, windowed eagerly returns the result, the full list of windows. If the required element is found in the very first list, it’s not efficient. The change to Sequence causes the result to be evaluated lazily, which means the snapshots are built only when they’re actually needed.
The change to sequences only requires one line. We convert a list to a sequence before performing any further operations:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumber(): Long? =
asSequence()
.windowed(GROUP_SIZE + 1)
.firstOrNull { window ->
val prevGroup = window.dropLast(1)
!prevGroup.hasPairOfSum(sum = window.last())
}
?.last()
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumber()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
That’s it! We’ve improved the solution from the very first version, making it more “idiomatic” along the way.
The last thing to do is to get the result for our challenge. We read the input, convert it to a list of numbers, and display the invalid one:
fun main() {
val numbers = File("src/day09/input.txt")
.readLines()
.map { it.toLong() }
val invalidNumber = numbers.findInvalidNumber()
println(invalidNumber)
}
For the sample input, the answer is 127, and for real input, the answer is also correct! Let’s now move on to solve the second part of the task.
Encoding error, part II
The second part of the task requires us to use the invalid number we just found. We need to find a contiguous set of at least two numbers in the list which sum up to this invalid number. The result we are looking for is the sum of the smallest and largest number in this contiguous range.
For the sample list, we need to find a contiguous list which sums to 127:
In this list, adding up all of the numbers from 15 through 40 produces 127. To find the result, we add together the smallest and largest number in this contiguous range; in this example, these are 15 and 47, producing 62.
Solution, part II
We need to find a sublist in a list with the given sum of its elements. Let’s first implement this function in a straightforward manner, then rewrite the same logic using library functions. We’ll discuss whether the windowed function from the previous part can help us here as well, and finally we’ll identify a more efficient solution.
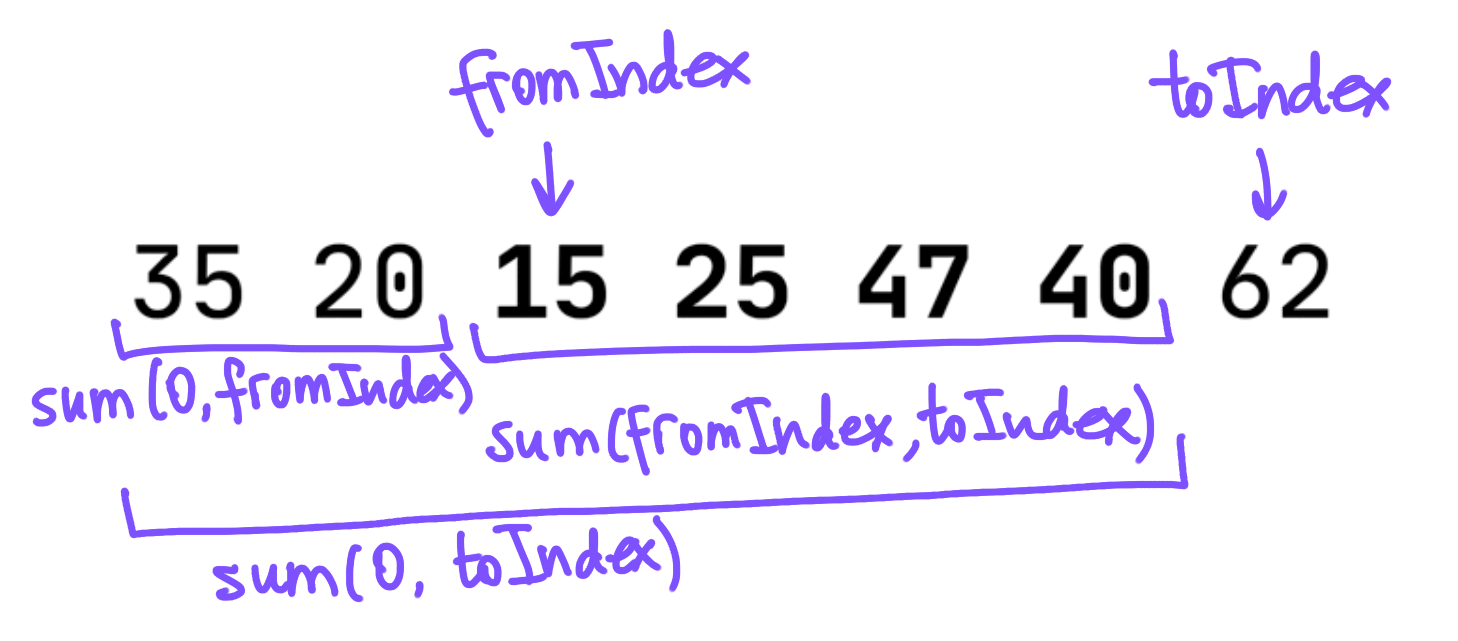
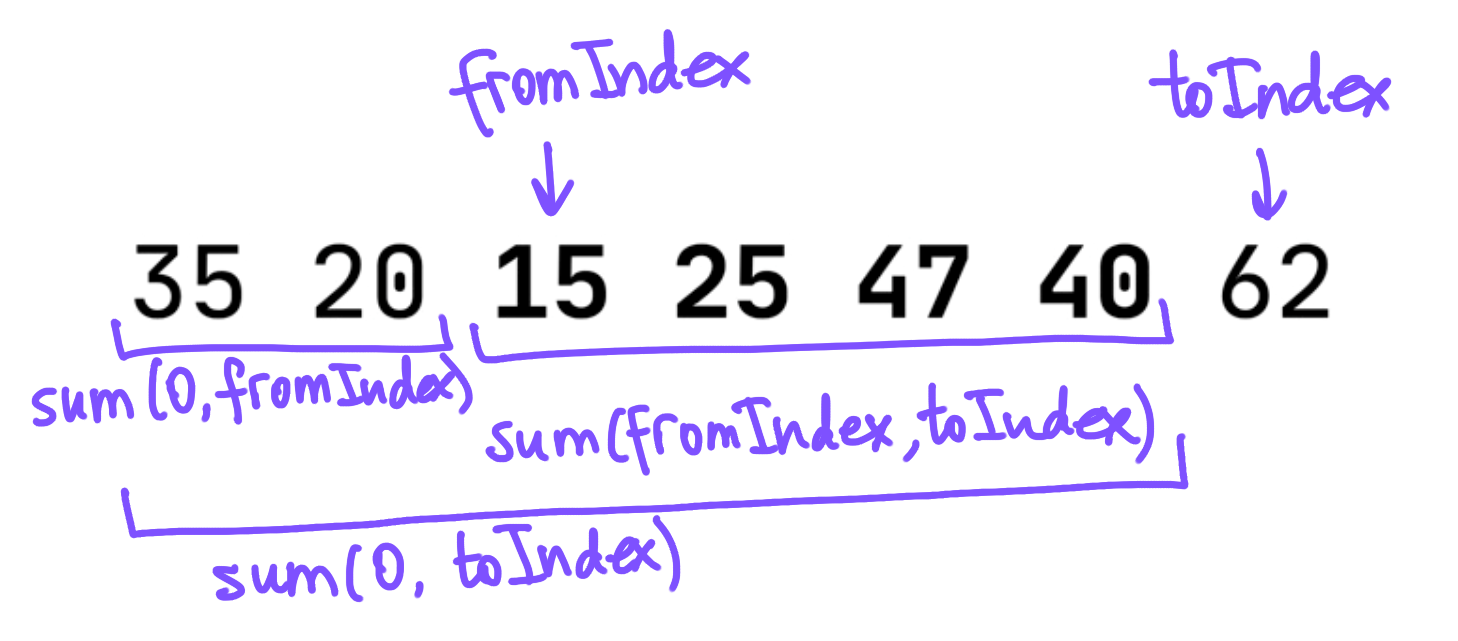
To check the sum of every contiguous sublist of a given list, we try all the options for the list’s start and end indices, build each sublist, and calculate its sum. fromIndex belongs to a full range of indices, while toIndex should be greater than fromIndex and shouldn’t exceed the list size (the toIndex argument defines an exclusive, not inclusive, upper bound):
fun List<Long>.findSublistOfSumV1(targetSum: Long): List<Long>? {
for (fromIndex in indices) {
for (toIndex in (fromIndex + 1)..size) {
val subList = subList(fromIndex, toIndex)
if (subList.sum() == targetSum) {
return subList
}
}
}
return null
}
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576
)
println(numbers.findSublistOfSumV1(127)) // [15, 25, 47, 40]
}
We can rewrite this logic using the firstNotNullOfOrNull function. Here, we iterate over possible values for fromIndex and for toIndex and look for the first value that satisfies the given condition:
The logic hasn’t changed, we’ve simply rewritten it using the firstNotNullOfOrNull. If a sublist with the required sum is found, it’s returned from both firstNotNullOfOrNull calls as the first found non-null value.
The takeIf function returns its receiver if it satisfies the given condition or null if it doesn’t. In this case, the takeIf call returns the found sublist if the sum of its elements is equal to the provided targetSum.
An alternative way to solve this problem is, for each possible sublist size, to build all the sublists of this size using the windowed function, and then check the sum of its elements:
As before, we convert the input list to a sequence to perform the operation in a lazy manner: each new sublist is created when it needs to be checked for sum.
All the functions we’ve considered so far work for the challenge input and give the correct answer, but they have one common disadvantage: they manipulate the sublists of all possible sizes, and for each one, calculate the sum. This approach isn’t the most efficient. We can do better, can’t we?
We can precalculate all the sums of sublists from the first element in the list to each element, and use these “prefix” sums to easily calculate the sum between any two elements. If we have the sum of elements from 0 to fromIndex, and the sum of elements from 0 to toIndex, the sum of the elements from fromIndex to toIndex can be found by subtracting the former from the latter:
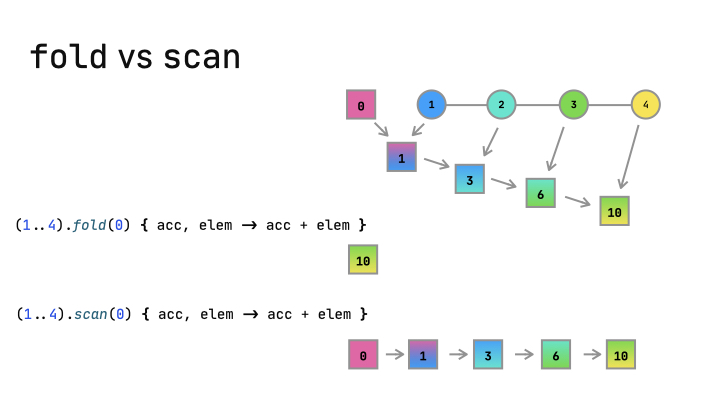
We need to precalculate the prefix sum for each element. We can use the standard library’s scan function for that! It also has another name, runningFold.
The fold and scan(runningFold) functions are related:
They both “accumulate” value starting with the initial value. On each step, they apply the provided operation to the current accumulator value and the next element.
fold returns only the final result, while scan(runningFold) returns the results for all the intermediate steps.
In this solution, we explicitly build only one sublist of the required sum to return it as the result.
Let’s now call the findSublistOfSum function to find the result for our initial challenge. After we found the invalid number in part I, we pass this value as an argument to the findSublistOfSum function, and then find the sum of the minimum and maximum values of the resulting list:
fun main() {
val numbers = File("src/day09/input.txt")
.readLines()
.map { it.toLong() }
val invalidNumber = numbers.findInvalidNumber()
?: error("All numbers are valid!")
println("Invalid number: $invalidNumber")
val sublist = numbers.findSublistOfSum(sum = invalidNumber)
?: error("No sublist is found!")
println(sublist.minOf { it } + sublist.maxOf { it })
}
Note how we use the error function to report an error and throw an exception in the event that one of our functions returns null. In AdventOfCode puzzles, we assume that the input is correct, but it’s still useful to handle errors properly.
That’s all! We’ve discussed the solution for the Day 9 AdventOfCode challenge and worked with the any, firstOrNull, firstNotNullOfOrNull, windowed, takeIf and scan functions, which exemplify a more idiomatic Kotlin style.
This post continues our “Idiomatic Kotlin” series and provides the solution for the Advent of Code Day 9* challenge. While solving it, we’ll look into different ways to manipulate lists in Kotlin.
Day 9. Encoding error, part I
We need to attack a weakness in data encrypted with the eXchange-Masking Addition System (XMAS)! The data is a list of numbers, and we need to find the first number in the list (starting from the 26th) that is not the sum of any 2 of the 25 numbers before it. We’ll call the number valid if it can be presented as a sum of two numbers from the previous sublist, and invalid otherwise. Two numbers that sum to a valid number must be different from each other.
If the first 25 numbers are 1 through 25 in a random order, the next number must be the sum of two of those numbers to be valid:
26 would be a valid next number, as it could be 1 plus 25 (or many other pairs, like 2 and 24).
49 would be a valid next number, as it is the sum of 24 and 25.
100 would not be valid; no two of the previous 25 numbers sum to 100.
50 would also not be valid; although 25 appears in the previous 25 numbers, the two numbers in the pair must be different.
Solution, part I
Let’s solve the task in Kotlin! For a start, let’s implement a function that checks whether a given list contains a pair of numbers that sum up to a given number. We’ll later use this function to check whether a given number is valid by passing this number and the list of the previous 25 numbers as arguments.
For convenience, we can define the function as an extension on a List of Long numbers. We need to iterate over all the elements in the list, looking for the two with the given sum. The first naive attempt will be using forEach (we call it on this implicit receiver, our list of numbers) to iterate through the elements twice:
fun List<Long>.hasPairOfSumV1(sum: Long): Boolean {
forEach { first ->
forEach { second ->
if (first + second == sum) return true
}
}
return false
}
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSumV1(26)) // true; 26 = 1 + 25
println(numbers.hasPairOfSumV1(49)) // true; 49 = 24 + 25
println(numbers.hasPairOfSumV1(100)) // false
// This is wrong:
println(numbers.hasPairOfSumV1(50)) // true; 50 = 25 * 2
}
But this solution is wrong! Using this approach, first and second might refer to the same element. But as we remember from the task description, two numbers that sum to a valid number must be different from each other.
To fix that, we can iterate over a list of elements with indices and make sure that the indices of two elements are different:
fun List<Long>.hasPairOfSumV2(sum: Long): Boolean {
forEachIndexed { i, first ->
forEachIndexed { j, second ->
if (i != j && first + second == sum) return true
}
}
return false
}
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSumV2(50)) // false
}
This way, if first and second both refer to 25, they have the same indices, so they are no longer interpreted as a correct pair.
We can rewrite this code and delegate the logic for finding the necessary element to Kotlin library functions. For this case, any does the job. It returns true if the list contains an element that satisfies the given condition:
//sampleStart
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
//sampleEnd
fun main() {
val numbers = listOf(1L, 24, 25, 10, 13)
println(numbers.hasPairOfSum(50)) // false
}
Our final version of the hasPairOfSum function uses any to iterate through indices instead of elements and checks for a pair that meets the condition. indices is an extension property on Collection that returns an integer range of collection indices, 0..size - 1; we call it on this implicit receiver, our list of numbers.
Finding an invalid number
Let’s implement a function that looks for an invalid number, one that is not the sum of two of the 25 numbers before it.
Before we start, let’s store the group size, 25, as a constant. We have a sample input that we can check our solution against which uses the group size 5 instead, so it’s much more convenient to change this constant in one place:
const val GROUP_SIZE = 25
We define the group size as const val and make it a compile-time constant, which means it’ll be replaced with the actual value at compile time. Indeed, if you use this constant (e.g. in a range GROUP_SIZE..lastIndex) and look at the bytecode, you’ll no longer be able to find the GROUP_SIZE property. Its usage will have been replaced with the constant 25.
For convenience, we can again define the findInvalidNumber function as an extension function on List. Let’s first implement it more directly, and then rewrite it using the power of standard library functions.
We use the example provided with the problem, where every number but one is the sum of two of the previous 5 numbers; the only number that does not follow this rule is 127:
//sampleStart
const val GROUP_SIZE = 5
fun List<Long>.findInvalidNumberV1(): Long? {
for (index in (GROUP_SIZE + 1)..lastIndex) {
val prevGroup = subList(index - GROUP_SIZE, index)
if (!prevGroup.hasPairOfSum(sum = this[index])) {
return this[index]
}
}
return null
}
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV1()) // 127
}
//sampleEnd
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
Because we need to find the first number in the input list that satisfies our condition starting from the 26th, we iterate over all indices starting from GROUP_SIZE + 1 up to the last index, and for each corresponding element check whether it’s invalid. prevGroup contains exactly GROUP_SIZE elements, and we run hasPairOfSum on it, providing the current element as the sum to check. If we find an invalid element, we return it.
You may think that the sublist() function creates the sublists and copies the list content, but it doesn’t! It merely creates a view. By using it, we avoid having to create many intermediate sublists!
We can rewrite this code using the firstOrNull library function. It finds the first element that satisfies the given condition. This allows us to find the index of the invalid number. Then we use let to return the element staying at the found position:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumberV2(): Long? =
((GROUP_SIZE + 1)..lastIndex)
.firstOrNull { index ->
val prevGroup = subList(index - GROUP_SIZE, index)
!prevGroup.hasPairOfSum(sum = this[index])
}
?.let { this[it] }
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV2()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
Note how we use safe access together with let to transform the index if one was found. Otherwise null is returned.
Using ‘windowed’
To improve readability, we can follow a slightly different approach. Instead of iterating over indices by hand and constructing the necessary sublists, we use a library function that does the job for us.
The Kotlin standard library has the windowed function, which returns a list or a sequence of snapshots of a window of a given size. This window “slides” along the given collection or sequence, moving by one element each step:
Here we build sublists, that is, snapshots, of size 2 and 3. To see more examples of how to use windowed and other advanced operations on collections, check out this video.
This function is perfectly suited to our challenge, as it can build sublists of the required size automatically for us. Let’s rewrite findInvalidNumber once more:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumberV3(): Long? =
windowed(GROUP_SIZE + 1)
.firstOrNull { window ->
val prevGroup = window.dropLast(1)
!prevGroup.hasPairOfSum(sum = window.last())
}
?.last()
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumberV3()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
To have both the previous group and the current number, we use a window with the size GROUP_SIZE + 1. The first GROUP_SIZE elements form the necessary sublist to check, while the last element is the current number. If we find a sublist that satisfies the given condition, its last element is the result.
Note about the difference between sublist and windowed functions
Note, however, that unlike sublist(), which creates a view of the existing list, the windowed() function builds all the intermediate lists. Though using it improves readability, it results in some performance drawbacks. For parts of the code that are not performance-critical, these drawbacks usually are not noticeable. On the JVM, the garbage collector is very effective at collecting such short-lived objects. It’s nevertheless useful to know about these nuanced differences between the two functions!
There’s also an overloaded version of the windowed() function that takes lambda as an argument describing how to transform each window. This version doesn’t create new sublists to pass as lambda arguments. Instead, it passes “ephemeral” sublists (somewhat similar to sublist() views) that are valid only inside the lambda. You should not store such a sublist or allow it to escape unless you’ve made a snapshot of it:
fun main() {
val list = listOf('a', 'b', 'c', 'd', 'e')
// Intermediate lists are created:
println(list.windowed(2).map { it.joinToString("") })
// Lists passed to lambda are "ephemeral",
// they are only valid inside this lambda:
println(list.windowed(2) { it.joinToString("") })
// You should make a copy of a window sublist
// to store it or pass further:
var firstWindowRef: List<Char>? = null
var firstWindowCopy: List<Char>? = null
list.windowed(2) {
if (it.first() == 'a') {
firstWindowRef = it // Don't do this!
firstWindowCopy = it.toList()
}
it.joinToString("")
}
println("Ref: $firstWindowRef") // [d, e]
println("Copy: $firstWindowCopy") // [a, b]
}
If you try to store the very first window [a, b] by copying the reference, you see that by the end of the iterations this reference contains different data, the last window. To get the first window, you need to copy the content.
A function with similar optimization might be added in the future for Sequences, see KT-48800 for details.
We can further improve our findInvalidNumber function by using sequences instead of lists. In Kotlin, Sequence provides a lazy way of computation. In the current solution, windowed eagerly returns the result, the full list of windows. If the required element is found in the very first list, it’s not efficient. The change to Sequence causes the result to be evaluated lazily, which means the snapshots are built only when they’re actually needed.
The change to sequences only requires one line. We convert a list to a sequence before performing any further operations:
const val GROUP_SIZE = 5
//sampleStart
fun List<Long>.findInvalidNumber(): Long? =
asSequence()
.windowed(GROUP_SIZE + 1)
.firstOrNull { window ->
val prevGroup = window.dropLast(1)
!prevGroup.hasPairOfSum(sum = window.last())
}
?.last()
//sampleEnd
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576)
println(numbers.findInvalidNumber()) // 127
}
fun List<Long>.hasPairOfSum(sum: Long): Boolean =
indices.any { i ->
indices.any { j ->
i != j && this[i] + this[j] == sum
}
}
That’s it! We’ve improved the solution from the very first version, making it more “idiomatic” along the way.
The last thing to do is to get the result for our challenge. We read the input, convert it to a list of numbers, and display the invalid one:
fun main() {
val numbers = File("src/day09/input.txt")
.readLines()
.map { it.toLong() }
val invalidNumber = numbers.findInvalidNumber()
println(invalidNumber)
}
For the sample input, the answer is 127, and for real input, the answer is also correct! Let’s now move on to solve the second part of the task.
Encoding error, part II
The second part of the task requires us to use the invalid number we just found. We need to find a contiguous set of at least two numbers in the list which sum up to this invalid number. The result we are looking for is the sum of the smallest and largest number in this contiguous range.
For the sample list, we need to find a contiguous list which sums to 127:
In this list, adding up all of the numbers from 15 through 40 produces 127. To find the result, we add together the smallest and largest number in this contiguous range; in this example, these are 15 and 47, producing 62.
Solution, part II
We need to find a sublist in a list with the given sum of its elements. Let’s first implement this function in a straightforward manner, then rewrite the same logic using library functions. We’ll discuss whether the windowed function from the previous part can help us here as well, and finally we’ll identify a more efficient solution.
To check the sum of every contiguous sublist of a given list, we try all the options for the list’s start and end indices, build each sublist, and calculate its sum. fromIndex belongs to a full range of indices, while toIndex should be greater than fromIndex and shouldn’t exceed the list size (the toIndex argument defines an exclusive, not inclusive, upper bound):
fun List<Long>.findSublistOfSumV1(targetSum: Long): List<Long>? {
for (fromIndex in indices) {
for (toIndex in (fromIndex + 1)..size) {
val subList = subList(fromIndex, toIndex)
if (subList.sum() == targetSum) {
return subList
}
}
}
return null
}
fun main() {
val numbers = listOf<Long>(
35, 20, 15, 25, 47, 40, 62,
55, 65, 95, 102, 117, 150, 182,
127, 219, 299, 277, 309, 576
)
println(numbers.findSublistOfSumV1(127)) // [15, 25, 47, 40]
}
We can rewrite this logic using the firstNotNullOfOrNull function. Here, we iterate over possible values for fromIndex and for toIndex and look for the first value that satisfies the given condition:
The logic hasn’t changed, we’ve simply rewritten it using the firstNotNullOfOrNull. If a sublist with the required sum is found, it’s returned from both firstNotNullOfOrNull calls as the first found non-null value.
The takeIf function returns its receiver if it satisfies the given condition or null if it doesn’t. In this case, the takeIf call returns the found sublist if the sum of its elements is equal to the provided targetSum.
An alternative way to solve this problem is, for each possible sublist size, to build all the sublists of this size using the windowed function, and then check the sum of its elements:
As before, we convert the input list to a sequence to perform the operation in a lazy manner: each new sublist is created when it needs to be checked for sum.
All the functions we’ve considered so far work for the challenge input and give the correct answer, but they have one common disadvantage: they manipulate the sublists of all possible sizes, and for each one, calculate the sum. This approach isn’t the most efficient. We can do better, can’t we?
We can precalculate all the sums of sublists from the first element in the list to each element, and use these “prefix” sums to easily calculate the sum between any two elements. If we have the sum of elements from 0 to fromIndex, and the sum of elements from 0 to toIndex, the sum of the elements from fromIndex to toIndex can be found by subtracting the former from the latter:
We need to precalculate the prefix sum for each element. We can use the standard library’s scan function for that! It also has another name, runningFold.
The fold and scan(runningFold) functions are related:
They both “accumulate” value starting with the initial value. On each step, they apply the provided operation to the current accumulator value and the next element.
fold returns only the final result, while scan(runningFold) returns the results for all the intermediate steps.
In this solution, we explicitly build only one sublist of the required sum to return it as the result.
Let’s now call the findSublistOfSum function to find the result for our initial challenge. After we found the invalid number in part I, we pass this value as an argument to the findSublistOfSum function, and then find the sum of the minimum and maximum values of the resulting list:
fun main() {
val numbers = File("src/day09/input.txt")
.readLines()
.map { it.toLong() }
val invalidNumber = numbers.findInvalidNumber()
?: error("All numbers are valid!")
println("Invalid number: $invalidNumber")
val sublist = numbers.findSublistOfSum(sum = invalidNumber)
?: error("No sublist is found!")
println(sublist.minOf { it } + sublist.maxOf { it })
}
Note how we use the error function to report an error and throw an exception in the event that one of our functions returns null. In AdventOfCode puzzles, we assume that the input is correct, but it’s still useful to handle errors properly.
That’s all! We’ve discussed the solution for the Day 9 AdventOfCode challenge and worked with the any, firstOrNull, firstNotNullOfOrNull, windowed, takeIf and scan functions, which exemplify a more idiomatic Kotlin style.
Today in “Idiomatic Kotlin”, we’re solving another Advent of Code challenge. We will be simulating, diagnosing, and fixing a small, made up game console! If you have ever wanted to implement your own virtual machine or emulator for an existing system like a game console or a retro computing device, you’ll find this issue particularly interesting!
As usual, a number of Kotlin features will help us achieve that goal, like sealed classes, sequences, and immutability.
A passenger on our flight hands us a little retro game console that won’t turn on. It somehow seems to be stuck in an infinite loop, executing the same program over and over again. We want to help them by fixing it!
To do so, we first need to run a simulation of the program on our own. At a later point, we want to fix the console so that it no longer gets stuck in a loop. Because the input for this challenge contains a lot of information, we’ll spend some time dissecting it together.
The input for our challenge is a bunch of instructions, which are executed by the gaming device. If you’ve ever delved into how computers work, you might recognize this as some kind of “Assembly Language” – essentially simple low-level instructions for a processor that are executed one after the other, top down, without all the fancy bells and whistles that higher-level languages offer:
By looking through the code and the problem description, we can identify three different types of instructions: nop, jmp, and acc, which always come with a numeric value. We can use the industry standard terms to refer to the parts of an instruction. The first part (nop / jmp / acc) is called the “opcode”. The second part of the instruction is called the “immediate value”.
Our problem statement gives us some hints about how to interpret the combination of opcodes and immediate values.
The nop (No Operation) instruction doesn’t do anything besides advance to the following instruction. We can also ignore its immediate value for the time being.
The jmp (Jump) instruction jumps a given number of instructions ahead or back, based on its immediate value.
The acc (Accumulator) instruction modifies the only real memory of our little device, its “accumulator” register, which can save the result of additions or subtractions, again based on the immediate value that follows.
Based on this understanding of the input for our challenge, we can make some deductions that help us model the machine in Kotlin.
The first one of those is that the current state of the machine can be fully described with two numbers:
The accumulator, which is the result of any calculations that we’ve made so far.
The index for the next instruction that we want to execute. In computing, this is called the “instruction pointer” or “program counter”.
This graphic shows that indeed, the only moving parts in our machine are the accumulator and the instruction pointer. For a step-by-step walkthrough, be sure to watch the video accompanying this blog post.
The second observation is that instructions behave just like functions that take an accumulator and instruction pointer as inputs and return a new accumulator and instruction pointer as outputs. This graphic shows how the acc instruction acts like a function, but the same applies for the nop and jmp instructions, as well:
We are now armed with the knowledge we need to actually implement a simulator for this device. To recap:
The input for our program is a number of instructions in a list (the “program”)
Each instruction in our program can modify two things:
The instruction pointer, which determines the next instruction to be executed
The accumulator, which stores a single number
Our device continuously reads the instruction and executes it based on its current state. This process continues until we end up with an instruction pointer that is outside the bounds of our program, indicating termination.
Building a device simulator
With our understanding of the puzzle input, let’s move on to what we need in order to successfully run the program we’re given as a puzzle input. Because we’re told this program is stuck in some kind of loop, the actual “answer” to the challenge is going to be the value of the accumulator immediately before we execute an instruction a second time.
Before we even think about how to detect loops in such a program, let’s start by building a small simulator for the device.
Modeling the machine and its instructions
The first step is to model the machine’s state and its instructions. We determined that the state of the machine can be fully described using two numbers: the instruction pointer and the accumulator. We can model this pair as an immutable data class:
data class MachineState(val ip: Int, val acc: Int)
We then need to define the three different types of instructions that the machine understands. To do so, let’s create a small class hierarchy to represent the different types of instructions. This will allow us to share some attributes across all instructions and distinguish between the different types of instructions that we may encounter.
Because we figured out that an instruction can take a machine state and return a new machine state, we will attach an action attribute to all instructions. The action attribute is a function that transforms one machine state into a new one:
sealed class Instruction(val action: (MachineState) -> MachineState)
We also mark the Instruction class as sealed, allowing us to create subclasses for it and ensuring that the compiler is aware of all the subclasses for our Instruction class.
The first subclass we can tackle is the nop instruction. As per its name (“No Operation”), it does nothing but move on to the next instruction. Expressed in terms of the action associated with this instruction, it creates a new MachineState with an instruction pointer that is incremented by one. The accumulator remains unchanged. We can use the typical lambda syntax here to define our “action” function. It receives the previous MachineState as the implicitly named parameter it.
Because all nop instructions behave the same, we can use the object keyword to create a singleton object for them, instead of creating a whole class for this instruction:
The next instruction is the jmp instruction. We recall that the behavior of the jmp instruction only changes the instruction pointer, because that’s the part of the machine state that determines what instruction to run next. How far ahead or back the jump goes is determined by the attached immediate value – the accumulator once again remains unchanged:
Lastly, we implement the acc instruction, which adds its immediate value to the accumulator and increments the instruction pointer so that the program continues running with the next instruction:
With this model for state and instructions in place, we can move on to running a list of instructions, one after the other – a whole program.
Let’s write up a function called execute, which does exactly that: It starts the device with an initial state, where both instruction pointer and accumulator are zero. It performs a loop for as long as our instruction pointer is valid. Inside the loop, we read the instruction at the current index from our list. We then apply the action that is associated with that instruction, and feed it the current state of the machine. This returns a new state of the machine, from which we can continue execution. We can also add a quick call to println to ensure that this code actually runs as we expect it to.
If the program behaves correctly, then at some point the instruction pointer should go out of bounds – indicating that the program terminated. In this case, we can return the latest state of the machine. This would be our “happy path”. The finished function looks like this:
fun execute(instructions: List<Instruction>): MachineState {
var state = MachineState(0, 0)
while (state.ip in instructions.indices) {
val nextInstruction = instructions[state.ip]
state = nextInstruction.action(state)
println(state)
}
println("No loop found - program terminates!")
return state
}
To see if the function actually works, let’s also add the functionality required to read our program from the input text file. If you’ve followed along with the series, you probably already have a good idea of how we approach this: We open the file, read all of the lines of text inside, and turn them into Instruction objects by applying the map function.
val instructions = File("src/day08/input.txt")
.readLines()
.map { Instruction(it) }
Of course, we also need to actually figure out what kind of Instruction objects we actually want. To do so, we can write a small factory function, that does two things:
It uses the split function to turn the full lines into the instruction names and their associated value
It uses a when statement to instantiate the appropriate class – either nop, acc, or jmp
Note that this is one of the few situations where the Kotlin style guide expressly allows us to start a function with an uppercase letter. What we’re writing here is a “factory function”, which is intentionally allowed to look similar to a constructor call.
fun Instruction(s: String): Instruction {
val (instr, immediate) = s.split(" ")
val value = immediate.toInt()
return when (instr) {
"nop" -> Nop
"acc" -> Acc(value)
"jmp" -> Jmp(value)
else -> error("Invalid opcode!")
}
}
With these helper functions added to our program, we are ready to run it, passing the list of instructions we just parsed to the execute function:
fun main() {
println(execute(instructions))
}
When we run the program, we quickly notice that it does not terminate. This makes sense – our challenge was to find where our program begins infinitely looping and to see what the last machine state is exactly before we enter the loop a second time. But – at the very least – we have confirmed that something really is wrong with the input code for our challenge!
Detecting cycles and solving part 1
We can easily retrofit a simple kind of cycle detection into our execute function. To figure out when we see an instruction for the second time, we keep track of each instruction index we’ve encountered so far and save it in a Set. Whenever we’re done executing an instruction, we check whether our new instruction pointer contains a value that we’ve seen before. This would indicate that an instruction will be executed for a second time, meaning we can just return the current state of the machine:
fun execute(instructions: List<Instruction>): MachineState {
var state = MachineState(0, 0)
val encounteredIndices = mutableSetOf<Int>()
while (state.ip in instructions.indices) {
val nextInstruction = instructions[state.ip]
state = nextInstruction.action(state)
if (state.ip in encounteredIndices) return state
encounteredIndices += state.ip
}
println("No loop found - program terminates!")
return state
}
Running our simulator again, our program successfully detects the loop, and returns the last machine state before the cycle would continue. We enter the accumulator value as returned by the function on adventofcode.com, and celebrate our first star for this challenge!
Solving part 2
In the second part of the challenge, we go beyond just finding an error, and try our hand at fixing the program we’ve been presented. We receive an important hint in the problem statement: exactly one instruction is the root cause for the infinite loop. Somewhere in the long list of instructions, one of the jmp instructions is supposed to be a nop instruction, or vice versa.
We can apply a rather straightforward approach to attempt a solution. To find out which instruction needs fixing, we generate all possible versions of the program where a nop has been exchanged with a jmp and the other way around. We can then run them all and see whether any of them terminate.
We can apply a small optimization here and base our solution on Kotlin’s sequences, which allow us to do the same calculations, but in a lazy manner. By using sequences, our code will only generate those adjusted programs that we actually need, until we’ve found a working version, and then it will terminate. Essentially, we create a mutated program, execute it, and see whether it terminates. If it doesn’t, we create the next mutation and run the check again.
We can write a function called generateAllMutations, which takes the original program as its input and returns a sequence of other program codes that have been modified. Each element of that sequence will be a full program, but with one instruction exchanged.
We use the sequence builder to create a “lazy collection” of programs, by creating working copies of the original program and exchanging the appropriate instructions at the correct indices. Instead of returning a list of programs at the end, we “yield” an individual value. That is, we hand over a value to the consumer of our sequence. When our program hits this point, our code here actually stops doing work – until the next value in the sequence is requested, at which point we run the next iteration of our loop. The whole function looks like this:
fun generateAllMutations(instructions: List<Instruction>) = sequence<List<Instruction>> {
for ((index, instruction) in instructions.withIndex()) {
val newProgram = instructions.toMutableList()
newProgram[index] = when (instruction) {
is Jmp -> Nop(instruction.value)
is Nop -> Jmp(instruction.value)
is Acc -> continue
}
yield(newProgram)
}
}
To make this code work, we need to make some adjustments to the model of our machine instructions. We now know that we need the immediate values of nop operations in order to generate the corresponding jmp instructions. Thus, we turn the nopobject back into a full class with its very own immediate value:
class Nop(val value: Int)
This also requires a small change in the Instruction factory function, so that it properly parses the immediate value:
return when (instr) {
"nop" -> Nop(value)
To obtain our second star, we now feed our original program to the generateAllMutations function, and execute the sequence of new, altered programs using the map function. At this point, we have another sequence, this time of the results of the programs.
Because we’re only interested in the first one where the instruction pointer went outside of the instructions of our program, we use the first function with a predicate that expresses exactly that. This is also the so-called terminal operation of our chain of sequences. It turns a value from our sequence into the actual MachineState as returned by the execute function.
In a way, we have actually benefited from the fact that we just built a basic simulator first without caring too much about the detection of endless loops. Because we assumed that some programs might terminate, we handled that “happy path” correctly from the beginning. That just made it easier to get our second star by running our main function once more and submitting the last state of the machine before it terminates!
Performance considerations
Before we rest on our laurels, we can revisit our code a little more and talk about the implicit decisions that we made. One of the key factors that comes to mind with our implementation is its trade-off between immutability vs performance.
Maybe without realizing it, we’ve adopted an approach for defining and executing instructions that creates a lot of objects. Specifically, each time the action associated with an Instruction is invoked, a new MachineState object is created. This approach has pros and cons:
Generally speaking, using immutability like this can make it much easier to reason about your system. You don’t need to worry that somewhere, some code will change the internal state of the objects that you are referencing. While that may not apply here, it can become a really big deal, especially if your program uses concurrency (coroutines or threads). So it’s worth considering an approach like this from the get-go.
However, we’re also paying a price by allocating so many objects. For a small simulation like the one we have here, this approach is still possible, even when the task requires us to run like 600 modified programs. But if you’re writing a simulator for a real retro gaming device, or just any machine that can store more than a few numbers, this approach isn’t really applicable. Imagine having to copy the whole content of your machine’s RAM every time your CPU executes an instruction – you can probably see why that wouldn’t work.
One opinion on the topic that’s certainly worth reading is that of Kotlin Team Lead Roman Elizarov. He actually published an article called “Immutability we can afford”, where he talks about this. If you’re conscientious about how you’re architecting and optimizing your software, you might find this a compelling read.
A mutable implementation
To get a better understanding of the difference between an immutable and a mutable implementation, we can write a second version of the simulator, allowing us to examine some very basic performance characteristics.
Instead of completely rewriting the whole project, we can introduce a new executeMutably function with the same signature as our original execute function. The key difference in its implementation is the way the instruction pointer and accumulator are stored as mutable variables. This implementation also uses a when statement instead of relying on the action associated with an Instruction, which would always allocate a new MachineState:
fun executeMutably(instructions: List<Instruction>): MachineState {
var ip: Int = 0
var acc: Int = 0
val encounteredIndices = mutableSetOf<Int>()
while(ip in instructions.indices) {
when(val nextInstr = instructions[ip]) {
is Acc -> { ip++; acc += nextInstr.value }
is Jmp -> ip += nextInstr.value
is Nop -> ip++
}
if(ip in encounteredIndices) return MachineState(ip, acc)
encounteredIndices += ip
}
return MachineState(ip, acc)
}
From an outside perspective, this function behaves exactly like the original execute function. We can validate this by adding calls to it to our main function. We can also wrap these function calls in invocations of measureTimedValue. This is an experimental function in the Kotlin standard library that can measure how long it takes for the block that it is passed to execute, and also return the original return value of that block:
The measurements that we can obtain using this of course have obvious flaws: we only run the process once, and don’t take into account things like JVM warmup time and other factors that might influence the performance of our code. While both implementations terminate within a pretty reasonable timeframe, we are indeed paying a price when we use the version which makes heavy use of immutability:
If we wanted to perform more detailed and reliable measurements, we would be better off using a framework like kotlinx.benchmark. However, even these basic numbers can give us an idea of the magnitude in performance difference between the two implementations.
At the end of the day, performance considerations like this will ultimately be up to you. Programming is a game of trade-offs, and choosing one of these implementations is another one of them.
Wrapping up
In today’s issue, we’ve gone through a lot of thinking, coding, and problem solving! Let’s quickly recap what we saw today:
We saw how we can use sealed classes and lambdas to represent the instructions of our simulated device, making sure the compiler always looks over our shoulder and ensures that we handle all instructions correctly, even when creating alternative versions of our input program.
We built a basic run cycle for our simulator, making sure we modified the machine state according to the instructions we received. We used Kotlin sets to discover loops in the execution of those input programs.
We used sequences and the sequence builder function to construct a lazy collection of programs for our second challenge. We also saw how we would yield those sequence elements on demand.
Lastly, we took some performance metrics into consideration, evaluating a different approach for executing the program and doing some armchair benchmarking using the experimental measureTimedValue function.
Many of these topics are worth diving a little deeper into, and we’re also planning on covering many of them in future videos on our official channel. So, subscribe to our YouTube channel and hit the bell to receive notifications when we continue the Kotlin journey!
As usual, we’d like to say thanks to the folks behind Advent of Code, specifically Eric Wastl, who gave us permission to use the Advent of Code problem statements for this series. Check out adventofcode.com, and continue puzzling on your own.
Let’s describe our task briefly. We are airport luggage throwers handlers, and as often happens, there are some new regulations. This time, they stipulate that all bags be color-coded and contain a specific number of color-coded bags inside them. Weird, right? Well, rules are rules, so we must comply. Let’s see what they look like:
Our mission is to find how many bags eventually contain at least one shiny gold bag.
It would be hard to find potential container bags for our shiny gold bag by hand, but programming will help us! To solve this task, we will implement a couple of search algorithms.
Part 1
We will work with a tree of bags. Trees are a good way to represent structures where things are contained in other things. The most straightforward representation of the tree in our case will be a Map of Colors to Rules, where the key is a color or the contained bag and the rule is a set of colors of bags that potentially can contain our bag.
Let’s define a couple of type aliases for that.
typealias Color = String
typealias Rule = Set<String>
We also know that the most important bag for us is the shiny gold bag. Let’s put that into a constant.
private const val SHINY_GOLD = "shiny gold"
And now, let’s define the function that will return our tree of rules.
fun main() {
val rules: Map<Color, Rule> = buildBagTree()
}
Now it’s time to start the first part of the solution: file parsing. Looking at our file again, we see each line is structured in the same way, including:
The name of the container bag
The word “bags”
The word “contain”
A single-digit number representing how many bags it contains
A comma-separated list of bags that the container bag contains
To process all the lines, we’ll remove all of the words “bags” or “bag”, all of the dots, and then the word “contain” from our string. Now, everything to the left of “contain” will be the container bag’s name and color, and everything to the right of “contain” will be the name of contained bags. In this part of the puzzle, we don’t need the numbers that the rules mention, so let’s remove them too.
We’ll use regular expressions to remove these unnecessary parts. The regular expression for deleting single digits is simple, but the one for removing “bag” and “bags” with the following dot is a bit more complex:
private fun buildBagTree(): Map<Color, Rule> {
File("src/day07/input.txt")
.forEachLine { line ->
line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
}
TODO()
}
After the pruning is complete, we need to split the string at “contain” and trim each resulting string.
private fun buildBagTree(): Map<Color, Rule> {
File("src/day07/input.txt")
.forEachLine { line ->
line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
}
TODO()
}
Let’s put the computation result into two different variables with a destructuring declaration:
private fun buildBagTree(): Map<Color, Rule> {
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
}
TODO()
}
The parent variable will contain the first element of the array, and allChildren will contain the second element of the array. Both will be strings.
Now, we need to convert the allChildren string into separate elements. We split it at the comma and trim again for each child.
private fun buildBagTree(): Map<Color, Rule> {
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
}
val childrenColors = allChildren.split(',').map { it.trim() }.toSet()
TODO()
}
Our function needs to return a tree, so let’s define one:
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
val childrenColors = allChildren.split(',').map { it.trim() }.toSet()
}
TODO()
}
Now, for each child found, we’ll check whether there is already a rule for it. If there is one, we add one more parent to it, and if not, we create a new rule. Remember that the rule is just a typealias to the set of strings.
A special function on maps called compute allows us to calculate the next value for any given key. Let’s make use of it. Note that this function is JVM-specific, so if you’re using a different platform you’ll need to use something else, like an if expression.
In our case, the key is the color of the child. The compute function accepts two arguments: the first is a key we are looking for, and the second is a lambda that, in turn, takes two arguments, our key and the current value.
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
val childrenColors = allChildren.split(',').map { it.trim() }.toSet()
for (childColor in childrenColors) {
rules.compute(childColor) { key, value ->
TODO()
}
}
}
TODO()
}
The key type is String, and the value type is Set<String>?. Now we should define separate logics for the situation when the current value is null and when the current value is not null. When the rule is null, we create a new rule and return it as a new value. If the value is not null, we add a new parent to the existing rule.
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
val childrenColors = allChildren.split(',').map { it.trim() }.toSet()
for (childColor in childrenColors) {
rules.compute(childColor) { key, value ->
if (current == null) setOf(parent)
else current + parent
}
}
}
TODO()
}
The rule is represented with an immutable set, so we can use the plus operator, which will create a new set for us. value and key aren’t very meaningful names, so let’s rename them. It also looks like the key is not used at all here because we already know our key. Let’s replace it with a special underscore value so it won’t be underlined as unused. Parsing is finished, so let’s make this function return our rules:
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line
.replace(Regex("\d+"), "")
.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
val childrenColors = allChildren.split(',').map { it.trim() }.toSet()
for (childColor in childrenColors) {
rules.compute(childColor) { _, current ->
if (current == null) setOf(parent)
else current + parent
}
}
}
return rules
}
The next part is the actual search. How do we do that? Let’s use a depth-first search, a good algorithm for traversing trees or graphs.
For each iteration, we’ll define for which bags we need to find potential parents. The first step is to define our known bags, which is currently the “shiny gold” bag (result will be stored in the known variable). In the second step, we will find potential containers found on the first iteration (for the ”shiny gold” we know that there are at least some), et cetera, et cetera, until we finish the search. The result of an iteration will be called next.
If all of the next bags are already known, then we’ll break the cycle.
Otherwise, we’ll redefine our already known bags and the next step with new values. The most exciting part here is defining the new step. It will be the potential containers of each bag in the current toFind set. For each item in the toFind set, we’ll find its containers in rules, and then flatten the search results and convert them to a set to remove any duplicates.
fun findContainersDFS(rules: Map<Color, Rule>): Set<Color> {
var known = setOf(SHINY_GOLD)
var next = setOf(SHINY_GOLD) + rules[SHINY_GOLD]!!
while (true) {
val toFind = next - known
if (toFind.isEmpty()) break
known = known + next
next = toFind.mapNotNull { rules[it] }.flatten().toSet()
}
return known - SHINY_GOLD
}
It looks like our iterative search is finished. Let’s return the results from our search function and output the final result – the known bags without the shiny gold bag itself.
fun main() {
val rules: Map<Color, Rule> = buildBagTree()
val containers = findContainersDFS(rules)
println(containers)
println()
println(containers.size)
}
I run the program and my output is 274. It’s the correct answer for how many bags contain at least one shiny gold bag.
Now let’s move on to the second part of the puzzle.
Part 2
This time the input (the list of rules) is the same, but we need to count how many bags our shiny gold bag will eventually contain.
We’ll perform the same calculation, but this time we’ll go down the tree and use the numbers (which we threw out last time) in order to count how many bags each bag will contain, and we’ll do this recursively.
Let’s look at our input again. Rereading the rules gives us new information: some bags won’t contain other bags, according to lines such as “shiny green bags contain no other bags“. That would be the end of the recursion for that kind of bag.
Now we’re going to build the same tree, but the color of the container will be the key, and the info about children will be the rule. Let’s implement the parsing logic:
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
}
return rules
}
Now let’s compute our rule for the current parent. If there is a phrase “no other” in the “allChildren” variable, the rule will be empty. Otherwise, it will contain children split by comma, trimmed, and converted into a set.
private fun buildBagTree(): Map<Color, Rule> {
val rules = hashMapOf<Color, Rule>()
File("src/day07/input.txt")
.forEachLine { line ->
val (parent, allChildren) = line.replace(Regex("bags?\.?"), "")
.split("contain")
.map { it.trim() }
val rule =
if (allChildren.contains("no other")) emptySet()
else allChildren.split(',').map { it.trim() }.toSet()
rules[parent] = rule
}
return rules
}
Now we need to count the children inside the shiny gold bag with the help of a breadth-first search. A breadth-first search is an algorithm for searching a tree data structure for a node that satisfies a given property. It starts at the tree root and explores all nodes at the present depth before moving on to the nodes of the next level.
Let’s create a function for it – an extension function for our map for the sake of readability. As a parameter, it will accept the color of the bag children which we are counting.
private fun Map<Color, Rule>.getChildrenCountBFS(color: Color): Int {
TODO()
}
Remember how we kept the number of every child in the bag? Now let’s create a regular expression, which we’ll use to find the numbers in each child.
val digits = "\d+".toRegex()
We extract all children from the current bag at each level of iteration. If there are no other bags in it, we return zero.
private fun Map<Color, Rule>.getChildrenCountBFS(color: Color): Int {
val children = getOrDefault(color, setOf())
if (children.isEmpty()) return 0
TODO()
}
Now we declare the counter and start counting bags inside each child. First, we extract the count of this child in the parent bag to the variable “count”.
Second, we replace this count with nothing in the child’s name and trim the resulting name. We add to the total count and multiply by the number of bags inside each bag. On each level of recursion, we return the total after the loop:
private fun Map<Color, Rule>.getChildrenCountBFS(color: Color): Int {
val children = getOrDefault(color, setOf())
if (children.isEmpty()) return 0
var total = 0
for (child in children) {
val count = digits.findAll(child).first().value.toInt()
val bag = digits.replace(child, "").trim()
total += count + count * getChildrenCountBFS(bag)
}
return total
}
That’s it: the result is 158,730 and it’s correct!
This is what we learned about today:
How to use regular expressions
JVM-specific compute methods that allow us to dynamically calculate the value in the map based on the current value
Grouping and counting the characters in strings and collections is a very typical task given in coding interviews. Usually, the solutions for such tasks are quite simple. In this blog post, we learn about a few useful functions in Kotlin that make set operations really simple.
The task: custom customs
The task for the Advent of Code Day 6 challenge requires us to count the answers on customs declaration forms. We are provided with the results of the filled-in forms for different groups of people. Below is the original sample provided in the AoC Day 6 challenge:
abc
a
b
c
ab
ac
a
a
a
a
b
This list represents answers from 5 groups:
The first group contains one person who answered “yes” to 3 questions: a, b, and c.
The second group contains three people who collectively answered “yes” to 3 questions: a, b, and c.
The third group contains two people who collectively answered “yes” to 3 questions: a, b, and c.
The fourth group contains four people who collectively answered “yes” to only 1 question, a.
The last group contains one person who answered “yes” to only 1 question, b.
Our task is to calculate the total number of “yes” answers in each group. For the example above, that would be 3 + 3 + 3 + 1 + 1 = 11.
Sounds easy, right? It seems like we could solve this task by just iterating the data, counting, and summing it up to get the final result. Let’s try that!
Solving the puzzle
First, we need to read the data. We can use the File.readText() function and then trim off the whitespace at the beginning and the end of the file. As per the description, group answers are always separated by blank lines, so we’ll use two line separators to split our input into separate groups:
val newLine = System.lineSeparator()
val groups: List<string> = File("src/day06/input.txt")
.readText()
.trim()
.split("$newLine$newLine")</string>
The result is a list of strings. Each string in the list represents the data about a group of answers to the questions from the customs declaration form.
Our goal is to count the unique answers within the group. We don’t need to count the answers for each individual person. This boils down to counting the unique characters in the string that represents the answers of each group.
A naive approach to solving the task above would be to iterate over the list of strings, eliminate duplicate characters by converting each string to a set, and calculate the size of all the sets. The sum would be the final answer.
var total = 0
for (group in groups) {
total += group.replace(newLine, "").toSet().size
}
The group of answers is one string, but it may include answers from multiple people, one line per person. Line breaks should not be taken into account when counting the unique characters. Therefore, I’m removing the line breaks before converting them to a set.
The solution is simple, but can it be improved in any way? As you might have guessed – it can! In fact, summing up numbers by iterating over a data structure is a pretty common task. IntelliJ IDEA would even suggest using the sumOf function if we place the caret on the for loop and press Alt+Enter.
val total = groups.sumOf {
it.replace(newLine, "").toSet().size
}
The sumOf function eliminates the need for the mutable variable to calculate the total. The function comes from Kotlin’s standard library, and if we look at the implementation, it does exactly what we did above:
public inline fun <T> Iterable<T>.sumOf(selector: (T) -> Int): Int {
var sum: Int = 0.toInt()
for (element in this) {
sum += selector(element)
}
return sum
}
The selector parameter is the function that returns a number. In our task, that’s the size of the set with unique answers for the group.
The puzzle continues
There’s a second part to the task. Just like in real life – there’s a change in the requirements! According to the story, we have misread the rules for counting the answers in the group. Instead of finding the questions to which anyone answered “yes”, we need to find the questions to which everyone in the group answered “yes”. For the same input:
abc
a
b
c
ab
ac
a
a
a
a
b
The rules for counting the answers are the following:
In the first group, everyone (the 1 person) answered “yes” to all 3 questions: a, b, and c.
In the second group, there is no question to which everyone answered “yes”.
In the third group, there is 1 question to which everyone answered “yes”, a. Since some people did not answer “yes” to b or c, the answers to these questions don’t count.
In the fourth group, everyone answered yes to 1 question only, a.
In the fifth group, everyone (the 1 person) answered “yes” to 1 question, b.
The final answer is 3 + 0 + 1 + 1 + 1 = 6
Let’s make a plan for solving this task. We need to iterate over the list of answer groups (1). Each group is represented by a multi-line string, and each line in a string represents answers by an individual person. Hence, we need to split the string to analyze the individual answers (2). We need to find the characters that are present in each line in a group (3). Each line is “a set of answers” by an individual person. So, we have a number of sets and we need to find the elements that are included in all the sets. This means we need to find the intersection (4) of the sets and reduce (5) the sets to only those elements that belong to the intersection.
Luckily, intersect is a standard library function in Kotlin. Additionally, the collection of sets can be reduced to a single set with the reduce function.
var total = 0
for (group in groups) { // (1)
val answers: List<String> = group.split(newLine) // (2)
val answerSets: List<Set<Char>> = answers.map { it.toSet() } // (3)
val intersection: Set<Char> =
answerSets.reduce /* (5) */ { a, b -> a intersect b /* (4) */}
total += intersection.size
}
This is a reasonably straightforward approach for solving the task. However, we can definitely do better by using more functions from the Kotlin standard library.
We can logically split this code into two parts. First, we can shape the input into a data structure that can be used to implement the “business logic”. To do this, we need to split each string in the list that we have read from the file, and then we need to convert each element to a set. This can be implemented using the map function as follows:
val data = groups.map {
it.split(newLine).map { s -> s.toSet() }
}
Next, we need to find the characters that are found in all the sets for each group. The reduce and intersect operations are still applicable for this part.
Let’s take a look at the intersect function first. Given two sets of characters, “abc” and “cde”, the intersection is only the character “c”:
val setA = "abc".toSet()
val setB = "cde".toSet()
val setC = setA intersect setB
println(setC) // prints [c]
If there are more sets, we can chain the operations by iterating the list of sets:
val setA = "abc".toSet()
val setB = "cde".toSet()
val setC = "cfg".toSet()
val setD = "czy".toSet()
val list = listOf(setA, setB, setC, setD)
var result = setA
for (set in list) {
result = result intersect set
}
println(result) // prints [c]
The loop above is effectively the same as using the reduce function with the intersect operation as follows:
val setA = "abc".toSet()
val setB = "cde".toSet()
val setC = "cfg".toSet()
val setD = "czy".toSet()
val list = listOf(setA, setB, setC, setD)
val result = list.reduce { a, b -> a intersect b }
println(result) // prints [c]
All we need to do now is call the count() function on the result to get the number of answers that were the same in the specific group. The code looks like this:
val data = groups.map {
it.split(newLine).map(String::toSet)
}
var total = 0
for (listOfSets in data) {
total += listOfSets.reduce { a, b -> a intersect b}.count()
}
We can see a familiar pattern for summing up the total. This is definitely a hint that we can use the sumOf function to calculate the same:
val total = data.sumOf { it ->
it.reduce { a, b -> a intersect b }.count()
}
Now we can chain the operations to put all the calculations in one pipeline:
val total = groups.map {
it.split(newLine).map(String::toSet)
}.sumOf {
it.reduce { a, b -> a intersect b }.count()
}
This code looks concise, but it is not perfectly readable yet. You can see that we are using the implicit variable name, 'it', in both code blocks. First, in the part where we transform the grouped answers into sets. Then, when working with the sets to find the intersections. The variable type in the different blocks is also different.
To make this more readable, we recommend giving an explicit name to the lambda argument, instead of 'it', if the code blocks are chained like in our example.
val total = groups.map { group ->
group.split(newLine).map(String::toSet)
}.sumOf { groupAnswers ->
groupAnswers.reduce { a, b -> a intersect b }.count()
}
At this point, we can make an interesting observation: the first part of our task can be solved exactly like the second part, but using union instead of intersect. So here’s a crazy idea, what if we wanted to support the different operations within the same code. For this, we can extract the logic into a function and use the operation as a parameter for the function as follows:
private fun transformAndReduce(groups: List<String>, operation: (Set<Char>, Set<Char>) -> Set<Char>) =
groups.map { lines ->
lines.split(newLine).map(String::toSet)
}.sumOf { characters ->
characters.reduce { a, b -> operation(a , b) }.count()
}
val firstAnswer = transformAndReduce(groups, Set<Char>::union)
val secondAnswer = transformAndReduce(groups, Set<Char>::intersect)
For this specific task, this might be overthinking things a bit. However, it demonstrates the use of functional types as parameters quite well.
Summary
Today’s puzzle did not require a complex solution. The final solution makes use of a few standard library functions: map, reduce, sumOf, intersect, and union. Using these functions we are able to elegantly compose a data manipulation pipeline to solve the puzzle.
The scenario is quite common in real-life applications. Hopefully, the demo code will provide you with a good reference that you can use for your everyday tasks.
Let’s continue our journey of understanding what “idiomatic Kotlin” means and solve one more puzzle from the Advent of Code challenge. The puzzles are independent of each other, so you don’t need to check any of the previous ones we’ve already covered. Simply read through the following solution or watch the video. We hope you learn something new!
Day 5. Binary Boarding
We’re boarding the plane! We need to analyze the list of boarding passes and find the seat with the highest seat ID. Then we need to find the one seat missing from the list, which is ours. You can find the full task description at https://adventofcode.com/2020/day/5.*
A seat is specified as, for example, FBFBBFFRLR, where F means “front”, B means “back”, L means “left”, and R means “right”. The first 7 characters are either F or B and they specify exactly one of the 128 rows on the plane (numbered 0 through 127). The last three characters are either L or R; these specify exactly one of the 8 columns of seats on the plane (numbered 0 through 7). A more detailed encoding description is given on the puzzle page.
Every seat has a unique seat ID, calculated by multiplying the row by 8 and then adding the column.
The puzzle input is the list of boarding passes. The first task is to find the boarding pass in this list with the highest seat ID.
The second task is to find the missing boarding pass in the list. The flight is completely full, there’s only one missing boarding pass, and that’s our seat. However, some of the seats at the very front and back of the plane don’t exist on this aircraft, so they are missing from the list as well.
As usual, we suggest that you try to solve the task on your own before reading the solution. Here’s how you can set up Kotlin for this purpose.
Solution
Let’s first discuss the encoding of the boarding passes. Note how it is a nicely “hidden” binary representation of natural numbers! Let’s take a closer look.
Boarding pass: binary representation
First, let’s look at the rows. There are 128 rows on the plane, which are encoded with 7 “bits”. These bits are called F and B in the puzzle, but they carry the same meaning as 0 and 1 do in the binary representation. To extend the analogy, the way to identify the exact row based on the boarding pass is reminiscent of the algorithm used to convert a binary representation of the number to a decimal.
Let’s consider the provided example – the first seven characters of FBFBBFFRLR that decode the “row”. F means to take the “front”, or the lower half, while B is to take the “back”, or the upper half on each iteration. Taking the lower half is equivalent to not adding the corresponding power of two to the result (or multiplying it by zero), while taking the upper half is equivalent to adding it to the result (or multiplying it by one).
F = 0; B = 1
FB notation F B F B B F F
Bit 0 1 0 1 1 0 0
Index 6 5 4 3 2 1 0
2^Index 64 32 16 8 4 2 1
Decimal:
0 * 2^6 + 1 * 2^5 + 0 * 2^4 + 1 * 2^3 + 1 * 2^2 + 0 * 2^1 + 0 * 2^0 =
32 + 8 + 4 =
44
If this conversion is clear to you, you can skip the remaining explanations in this section and go directly to the Kotlin implementation. If not, please read the description of the conversion strategy on the task page and the following explanations carefully.
We start by considering the whole range, rows 0 through 127. The maximum value that can be decoded via 7 bits is 1111111, or 127 if converted to the decimal form: 27 - 1 = 26 + 25 + 24 + 23 + 22 + 21 + 20 = 127. Each bit is responsible for its part of the range: if it’s 1, we add the corresponding power of two to the result; if it’s 0, we skip it.
Bit correspondence
Bit index
Description of the task
Reworded in ‘binary representation’ terms
F = 0
6
F means to take the lower half, keeping rows 0 through 63.
We don’t add 26=64 to the result.
That keeps the result in the 0..(127-64) range, or 0..63.
B = 1
5
B means to take the upper half, keeping rows 32 through 63.
We add 25=32 to the result. That keeps the result in the range 32..63.
F = 0
4
F means to take the lower half, keeping rows 32 through 47.
We don’t add 24=16 to the result. That makes the possible range 32..(63-16), or 32..47.
B = 1
3
B means to take the upper half, keeping rows 40 through 47.
We add 23=8 to the result. That keeps the result in the range (32+8)..47, or 40..47.
B = 1
2
B keeps rows 44 through 47.
We add 22=4 to the result. That keeps the result in the range (40+4)..47, or 44..47.
F = 0
1
F keeps rows 44 through 45.
We don’t add 21=2. That makes the possible range 44..(47-2), or 44..45.
F = 0
0
The final F keeps the lower of the two, row 44.
We don’t add 20=1. That makes the result 44..(45-1), or simply 44.
Decoding column
Decoding the column follows the same logic, but now R takes the upper half and corresponds to bit 1, while L takes the lower half and corresponds to bit 0.
Let’s now consider the last 3 characters of FBFBBFFRLR.
L = 0; R = 1
RL notation R L R
Bit 1 0 1
Index 2 1 0
2^Index 4 2 1
Decimal:
1 * 2^2 + 0 * 2^1 + 1 * 2^0 =
4 + 1 =
5
The whole range represents columns 0 through 7. It’s the maximum value that can be encoded via three bits: 22 + 21 + 20 = 7.
R means to take the upper half, keeping columns 4 through 7. In other words, take 22=4 with the multiplier "1".
L means to take the lower half, keeping columns 4 through 5. In other words, take 21=2 with the multiplier "0".
The final R keeps the upper of the two, column 5. In other words, take 20=1 with the multiplier "1", making the result 4+1=5.
The last part is converting the row and the column numbers to the seat ID by using the formula: multiply the row by 8 and then add the column. For the sample boarding pass, the row is 44 and the column is 5, so this calculation gives the seat ID as 44 * 8 + 5 = 357.
Combining row and column
But if we look closer at this formula, we’ll notice that we don’t need to find the row and column separately! We can simply add all the row bits with indexes increased by three to the result (note that 8 = 23). This bit operation is formally called “left-shift”.
With a little bit of math, a Kotlin solution can almost fit on a single line! Let’s see how.
Converting boarding pass to seat ID
We only need to replace B/F and R/L with 1/0 notation, and then convert the resulting binary representation to an integer. Each of these operations is one function call:
fun String.toSeatID(): Int = this
.replace('B', '1').replace('F', '0')
.replace('R', '1').replace('L', '0')
.toInt(radix = 2)
fun main() {
println("0101100101".toInt(radix = 2)) // 357
println("FBFBBFFRLR".toSeatID()) // 357
}
The String.replace(oldChar: Char, newChar: Char) function replaces all occurrences of the old character with the new character. There are two more similar functions. If you need to replace each substring with a new string, pass the strings as arguments:
In order to replace each substring that matches the given regular expression, use another function taking Regex as an argument:
String.replace(regex: Regex, replacement: String)
The String.toInt(radix: Int) function parses the string receiver as an integer in the specified radix. In our case, we specify that the radix is two, so it parses the binary representation of the number.
There’s no need to reimplement the conversion algorithm from scratch when you can use the library functions – unless you specifically want to practice that, of course, but that’s not the goal of this puzzle.
We’ve got the seat ID from the boarding pass now and we can continue with the task.
Finding the maximum seat ID
As usual, we need to read the input first. After implementing the conversion function, it’s quite straightforward:
fun main() {
val seatIDs = File("src/day05/input.txt")
.readLines()
.map(String::toSeatID)
// ...
}
The seatIDs list is a list of integers, and the only thing left is finding the maximum in this list. There’s no need to implement it from scratch; we simply use the maxOrNull() library function:
fun main() {
val seatIDs = …
val maxID = seatIDs.maxOrNull()
println("Max seat ID: $maxID")
}
We’ve found the seat with the maximum seat ID.
Finding the vacant seat ID
The second part of the task is finding the vacant seat that is missing from the list. There’s guaranteed to be only one. However, we remember that some of the seats at the very front and back of the plane don’t exist on this aircraft, so they are missing as well. And so, we can’t simply iterate through the range from 1 to maxID and check for missing seats, as we would also “find” those at the very front and back.
Note, however, that our required vacant seat is not on the edge. This means it’s the only missing seat whose neighbors are both present in the list. So, we can check for this condition: that the seat itself must be missing (in other words, not occupied), but both its neighbors must be occupied.
First, to make our code more expressive, let’s add a function that checks whether a given seat is occupied. It checks that the given seat index belongs to the list of seat IDs provided as the input for our challenge. To make this check quickly, we convert the given list to a set:
fun main() {
val seatIDs: List<Int> = …
val occupiedSeatsSet = seatIDs.toSet()
fun isOccupied(seat: Int) = seat in occupiedSeatsSet
}
Kotlin allows us to create local functions, that is, functions inside other functions. That’s really convenient for the kind of short and simple function we need to write here: the isOccupied() function will capture the outer variable, occupiedSeatsSet, and we don’t need to pass it explicitly as a parameter.
Now the only thing left to do is find the desired seat index, when the seat is not occupied but the neighboring seats (with indices -1 and +1) are both occupied:
The whole main function that solves both parts of the task looks as follows:
fun main() {
val seatIDs = File("src/day05/input.txt")
.readLines()
.map(String::toSeatID)
val maxID = seatIDs.maxOrNull()!!
println("Max seat ID: $maxID")
val occupiedSeatsSet = seatIDs.toSet()
fun isOccupied(seat: Int) = seat in occupiedSeatsSet
val mySeat = (1..maxID).find { index ->
!isOccupied(index) && isOccupied(index - 1) && isOccupied(index + 1)
}
println("My seat ID: $mySeat")
}
Note that in order to use maxID as the upper bound of the range, we call !!, since the maxOrNull() function returns a nullable value. Specifically, it returns null if the list is empty.
Following the Kotlin philosophy, you might expect to find the max() function, throwing an exception if the list is empty. And you’d be right! However, in Kotlin 1.5 the max() function is deprecated, and in future versions it will be totally removed and replaced with a function throwing an exception. The max() function was present in the standard library starting with Kotlin 1.0 but returned a nullable value, and now the Kotlin team is slowly fixing this small discrepancy. Until the max() function reappears in the standard library, it’s fine to write maxOrNull()!! to explicitly highlight that you need the non-null value as a result, and you prefer an exception if the list is empty. Alternatively, to avoid using !!, you can use maxOf { it } for now.
That’s it! We outlined the strategy for solving the puzzle, recognized the binary encoding for the numbers, discussed how it works, and presented the solution in Kotlin, which is quite simple thanks to the Kotlin standard library functions.
Today in “Idiomatic Kotlin”, we’re looking at day 4 of the Advent of Code 2020 challenges, in which we tackle a problem that feels as old as programming itself: input sanitization and validation.
Day 4. Passport processing
We need to build a passport scanner that, given a batch of input text, can count how many passports are valid. You can find the complete task description at https://adventofcode.com/2020/day/4*.
The input is a batch of travel documents in a text file, separated by blank lines. Each passport is represented as a sequence of key-colon-value pairs separated by spaces or newlines. Our challenge is finding out how many passports are valid. For part one, “valid” means that they need to have all the required fields outlined by the security personnel: byr, iyr, eyr, hgt, hcl, ecl and pid (we conveniently ignore their request to validate the cid field).
Solving Day 4, Part 1
Like many challenges, we start by reading our puzzle input as text and trim off any extraneous whitespace at the beginning and the end of the file. As per the description, passports are always separated by blank lines. A blank line is just two “returns”, or newlines, in a row, so we’ll use this to split our input string into the individual passports:
val passports = File("src/day04/input.txt")
.readText()
.trim()
.split("nn", "rnrn")
(Note that depending on your operating system, the line separator in text files is different: On Windows, it is rn, on Linux and macOS, it’s n. Kotlin’s split method takes an arbitrary number of delimiters, allowing us to cover both cases directly.)
We now have a list of passport strings. However, working with lists of raw strings can quickly get confusing. Let’s use Kotlin’s expressive type system to improve the situation and encapsulate the string in a very basic Passport class.
class Passport(private val text: String) {
}
We then just map the results of our split-up input to Passport objects:
// . . .
.map { Passport(it) }
From the problem description, we remember that key-value pairs are either separated by spaces or newlines within a single passport. Therefore, to get the individual pairs, we once again split our input. The delimiters, in this case, are either a space or one of the newline sequences.
fun hasAllRequiredFields(): Boolean {
val fieldsWithValues = text.split(" ", "n", "rn")
}
We then extract the key from each passport entry. We can do so by mapping our combined fieldsWithValues to only the substring that comes before the colon:
fun hasAllRequiredFields(): Boolean {
val fieldsWithValues = text.split(" ", "n", "rn")
val fieldNames = fieldsWithValues.map { it.substringBefore(":") }
return fieldNames.containsAll(requiredFields)
}
The result of our function will be whether the fieldNames we extracted contain all required fields. The requiredFields collection can be taken directly from the problem statement and translated into a list:
To calculate our final number, and get our first gold star for the challenge, we need to count the passports for which our function hasAllRequiredFields returns true:
fun main() {
println(passports.count(Passport::hasAllRequiredFields))
}
With that, we have successfully solved the first part of the challenge and can set our sights on the next star in our journey.
Find the full code for the first part of the challenge on GitHub.
Solving Day 4, Part 2
In part two of the challenge, we also need to ensure that each field on the passport contains a valid value. We are given an additional list of rules to accomplish this task, which you can again find in the problem description. Years need to fall into specific ranges, as does a person’s height depending on the unit of measurement. Colors need to come from a prespecified list or follow certain patterns, and numbers must be correctly formatted.
A refactoring excursion
Before we start building the solution for part 2, let’s briefly reflect on our code and find possible changes that will make adding this functionality easier for us. At this point in the challenge, we know that our Passport class will need access to the different field names and their associated values. The classical data structure to store such kind of associative-dictionary information is a map. Let’s refactor our code to store passport information in a map instead of a string.
Because turning an input string into a map is still a process that’s associated with the Passport, I like encapsulating such logic in a companion object “factory” function. In this case, we can aptly call it fromString:
companion object {
fun fromString(s: String): Passport {
The implementation for fromString partially reuses the normalization logic we had previously used in the first part of this challenge and expands it to create a map directly via Kotlin’s associate function:
fun fromString(s: String): Passport {
val fieldsAndValues = s.split(" ", "n", "rn")
val map = fieldsAndValues.associate {
val (key, value) = it.split(":")
key to value
}
return Passport(map)
}
A Passport object now encapsulates a map of string keys and string values:
class Passport(private val map: Map<String, String>) {
Interestingly enough, this change makes the implementation of the first part of our challenge trivial. We can simply check that the key set of our map contains all required fields:
fun hasAllRequiredFields() = map.keys.containsAll(requiredFields)
Returning to solving part 2
For the second part of the challenge, we consider a passport valid if it contains all the required fields and has values that correspond to the official rules.
To ensure that all fields have valid values, we can use the all function to assert that a predicate holds true for every single key-value pair in our map:
fun hasValidValues(): Boolean =
map.all { (key, value) ->
We can distinguish the different types of fields using a when expression. In this first step, we distinguish the different cases based on the keys in our map:
when (key) {
Each key we know gets a branch in this when statement. They all need to return a boolean value – true if the field is okay, false if the field violates the rules. The surrounding all predicate will then use those results to determine whether the passport as a whole is valid.
The byr (Birth Year), iyr (Issue Year), and eyr (Expiration Year) fields all require their value to be a 4-digit number falling into a particular range:
"byr" -> value.length == 4 && value.toIntOrNull() in 1920..2002
"iyr" -> value.length == 4 && value.toIntOrNull() in 2010..2020
"eyr" -> value.length == 4 && value.toIntOrNull() in 2020..2030
Note that our combined use of toIntOrNull together with the infix function in allows us to discard any non-numeric values, and ensure that they fall in the correct range.
We can apply a very similar rule to the pid (Passport ID) field. We ensure that the length of the value is correct and ensure that all characters belong to the set of digits:
Validating ecl (eye color) just requires us to check whether the input is in a certain set of values, similar to the first part of our challenge:
"ecl" -> value in setOf("amb", "blu", "brn", "gry", "grn", "hzl", "oth")
At this point, we have two more fields to validate: hgt (Height) and hcl (Hair Color). Both of them are a bit more tricky. Let’s look at the hgt field first.
The hgt (Height) field can contain a measurement either in centimeters or inches. Depending on the unit used, different values are allowed. Thankfully, both “cm” and “in” are two-character suffixes. This means we can again use Kotlin’s when function, grab the last two characters in the field value and differentiate the validation logic for centimeters and inches. Like our other number-validation logic, we parse the integer and check whether it belongs to a specific range. To do so, we also remove the unit suffix:
"hgt" -> when (value.takeLast(2)) {
"cm" -> value.removeSuffix("cm").toIntOrNull() in 150..193
"in" -> value.removeSuffix("in").toIntOrNull() in 59..76
else -> false
}
The last field to validate is hcl (Hair Color), which expects a # followed by exactly six hexadecimal digits – digits from 0 through 9, and a through f. While Kotlin can parse base-16 numbers, we can use this case to show off the sledgehammer method for validating patterns – regular expressions. Those can be defined as Kotlin strings and converted using the toRegex function. Triple-quoted strings can help with escape characters:
"hcl" -> value matches """#[0-9a-f]{6}""".toRegex()
Our hand-crafted pattern matches exactly one hashtag, then six characters from the group of 0 through 9, a through f.
As a short aside for performance enthusiasts: toRegex is a relatively expensive function, so it may be worth moving this function call into a constant. The same also applies to the set used in the validation for ecl – currently, it is initialized on each test.
Because the whole when-block is used as an expression, we need to ensure that all possible branches are covered. In our case, that just means adding an else branch, which simply returns true – just because a passport has a field we don’t know about doesn’t mean it can’t still be valid.
else -> true
With that, we have covered every rule outlined to us by the problem statement. To get our reward, we can now just count the passports that contain all required fields and have valid values:
fun partTwo() {
println(passports.count { it.hasAllRequiredFields() && it.hasValidValues() })
}
We end up with a resulting number, which we can exchange for the second star. We’re clear for boarding our virtual flight. Though this was probably not the last challenge that awaits us…
Find the complete solution for the second part of the challenge on GitHub.
Conclusion
For today’s challenge, we came up with an elegant solution to validate specific string information, which we extracted using utility functions offered by the Kotlin standard library. As the challenge continued, we reflected on our code, identified more fitting data structures, and changed our logic to accommodate it. Using Kotlin’s when statement, we were able to keep the validation logic concise and all in one place. We saw multiple different ways of how to validate input – working with ranges, checking set membership, or matching a particular regular expression, for example.
Many real-world applications have similar requirements for input validation. Hopefully, some of the tips and tricks you’ve seen in the context of this little challenge will also be helpful when you need to write some validation logic on your own.
To continue puzzling yourself, check out adventofcode.com, whose organizers kindly permitted us to use their problem statements for this series.
If you want to see more solutions for Advent of Code challenges in the form of videos, subscribe to our YouTube channel and hit the bell to get notified when we continue our idiomatic journey. More puzzle solutions are coming your way!