

先日、kotlinx.serialization 1.2 がリリースされました! 当社のマルチプラットフォーム向けシリアル化ライブラリの最新バージョンにはいくつかの改善点が盛り込まれています。以下、その概要を紹介します。
- JSON のシリアル化がこれまでで最速に。 バージョン 1.2 では、JSON を型安全な Kotlin オブジェクトに解釈し、Kotlin オブジェクトをテキストとして表示する処理を過去のバージョンよりも最大で 2 倍も速く処理できるようになりました。
- Kotlin 1.5 で追加された型システムのサポート。 Kotlin の他のクラス同様に、値クラス(value class)・符号なしの数値を JSON に変換し、また元に戻すということができるようになりました。
-
新しくなった API ドキュメント を使用すれば、
kotlinx.serializationが提供するすべての機能を簡単に見つけられます。
バージョン 1.2 には、JSON フィールドの代替名に対するサポートが新しく盛り込まれているほか、それにより、Kotlin クラスから自動的に Protobuf スキーマを生成する新しい実験的なアプローチも提供されています。この機能については、ぜひご意見をお聞かせください!
それでは、今回の新バージョンに関する変更点や追加機能を一緒に見ていきましょう! 既に十分理解されているという方は、下のアップグレード手順にジャンプしていただいて構いません!
kotlinx.serialization 1.2 を始める!
これまでで最速となる JSON のエンコード・デコード
Kotlin クラスを JSON の文字列にエンコードする機能と JSON の文字列を Kotlin クラスに変換する機能は、kotlinx.serialization の機能の中で最も一般的に使用されるものであるため、当社は常にパフォーマンスの改善に取り組んでいます。

バージョン 1.2 では、kotlinx.serialization の内部構造が全面的に見直され、このコア機能のパフォーマンスが大幅に改善されています。 JSON デコーダー (テキストを Kotlin オブジェクトに変換) を書き直し、JSON エンコーダー (Kotlin オブジェクトをテキストに変換) に対する大幅な最適化も実施しました。
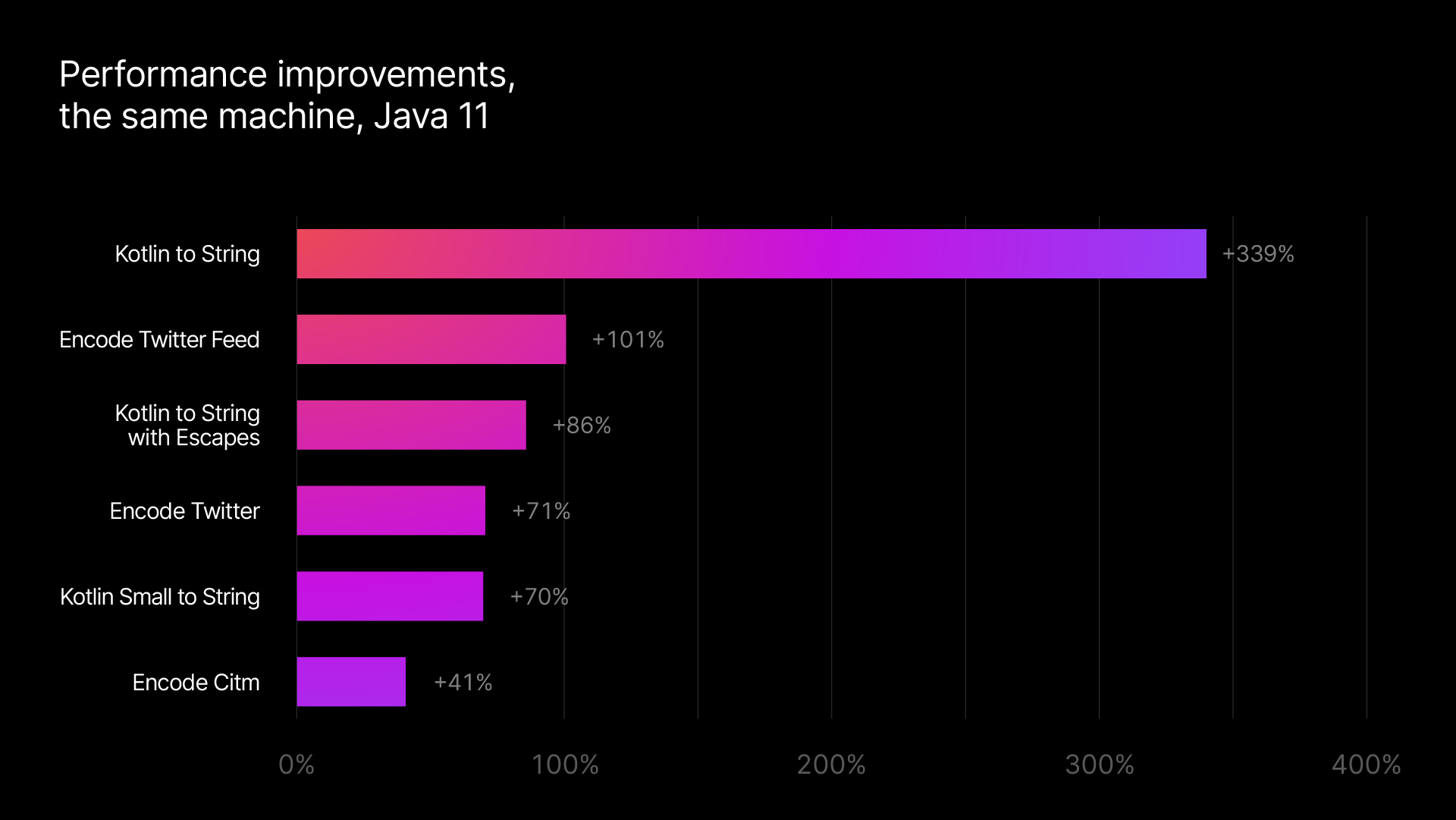
最新のライブラリにアップグレードするだけで、典型的なエンコードとデコードの処理速度が最高で 2 倍もアップすることが期待できます。 (見てお分かりの通り、内部ベンチマークの中には、こうした新しい最適化が大きなメリットとなり、この数字を超えるものもあります!)
こうした変更が加えられたことで、kotlinx.serialization は、そのままの状態で JSON の他のライブラリと同等のパフォーマンスを実現し、いくつかの点ではより高いレベルに達しています。 今回の見直しでは、とてもシンプルなスニペットにまでメリットがあります。
@Serializable
data class User(val name: String, val yearOfBirth: Int)
fun main() {
// Faster encoding...
val data = User("Louis", 1901)
val string = Json.encodeToString(data)
println(string) // {"name":"Louis","yearOfBirth":1901}
// ...and faster decoding!
val obj = Json.decodeFromString(string)
println(obj) // User(name=Louis, yearOfBirth=1901)
}
当社のライブラリの最新バージョンを基準にご自分のアプリケーションを評価すれば、こうした改善内容の効果を最も強く実感していただけると思います。 パフォーマンス数値の大まかな傾向は、エンコードとデコードに関する当社の内部ベンチマークをご覧ください。kotlinx.serialization の最新バージョンと前のリリースを比較した内容となっています。
値クラスと符号なしの数値型に対する JSON シリアル化 (逆シリアル化) が stable に
Kotlin 1.5.0 では、値クラスと符号なし整数型 という 2 つの便利な機能が追加されています。これらに対し、kotlinx.serialization 1.2 では、JSON のエンコードおよびデコードに対するファーストクラスのサポートが導入されました。 では、詳しく見てみましょう。
値クラスのサポート
値クラス (旧名 inline クラス) は、Kotlin の別の型 (number など) を実行時のオーバーヘッドを増やさずに型安全な手段を使ってラップするための方法です。 これにより、プログラムをより詳細に表現できるほか、安全性を高めることもできるため、パフォーマンスが低下することもありません。
kotlinx.serialization に備えられている JSON のシリアル化機能は値クラスに対しても使えるようになりました。 Kotlin の他のクラスと同様に、value class に @Serializable のアノテーションを付けるだけで OK です。
@Serializable value class Color(val rgb: Int)
値クラスは、その基底型として直接保存 (およびシリアル化) されます。 これは、value class 型のフィールドをシリアル化可能なデータクラスに追加し、その出力を検査すれば確認できます。
@Serializable
data class NamedColor(val color: Color, val name: String)
fun main() {
println(Json.encodeToString(NamedColor(Color(0), "black")))
}
// {"color": 0, "name": "black"}
上の例の NamedColor では、値クラス Color が 基底のプリミティブ型 (Int) として扱われています。 つまり、こうした型を正確にシリアル化した表現のメリットを得ながら、Kotlin コード内で最大の型安全を活用でき、不要なボックス化やネストは行う必要がありません。
値クラス用のカスタムシリアライザのデザインは、現在も改良中ですので、現時点でも実験的な使用となってます。 このトピックに関する詳細は、GitHub に記載のこちらの docs をご覧ください。
符号なし整数のサポート
符号なし整数は、Kotlin の標準ライブラリに新たに加わった種類の整数で、負以外の数値の型を使用したり、演算を行ったりすることができます。 Kotlin 1.5.0 のリリースにより、以下の符号なし数値型を使用できるようになりました。
-
UByte、0~255 の値 -
UShort、0~65535 の値 -
UInt、0~2^32 – 1 の値 -
ULong、0~2^64 – 1 の値
kotlinx.serialization の JSON エンコーダーとデコーダーは、初期設定の状態でこれらの型をサポートしています。 他の数値型と同様に、符号なし整数型も切り捨てやラッピング、符号付きの型への変換などはされずに、通常の数値表現 (.toString を呼び出したときと同じ表現) でシリアル化されます。
@Serializable
class Counter(val counted: UByte, val description: String)
@Serializable
class BigCounter(val counted: ULong)
val counted = 239.toUByte()
println(Json.encodeToString(Counter(counted, "tries")))
// {"counted":239,"description":"tries"}
println(Json.encodeToString(BigCounter(ULong.MAX_VALUE)))
// {"counted":18446744073709551615}
値クラスと符号なし整数の使用は、現在 JSON でサポートされています。 今後のリリースでは、CBOR と Protobuf の直接的な統合も提供しますので、ご期待ください!
kotlinx.serialization やプログラミング言語 Kotlin の今後のリリースに関する最新情報を把握しておきたい方は、本ブログ記事の横にあるフォームより Kotlin 製品の最新情報に関するニュースレターに登録してください。
kotlinx.serialization における値クラスと符号なし型の使用に関する詳細は、documentation on GitHub をご覧ください。
JSON フィールドに使う代替名のサポート
後方互換性を維持するためなどの理由から、意味は同じでも、名前が異なる JSON フィールドをパースしないといけない場合があります。 新しい @JsonNames アノテーションを使えば、JSON フィールドに代替名を付けられるようになりました。この代替名はデコーディングのプロセスを通して使用されます。
これを説明するために、例を 1 つ見てみましょう。 バージョンにより、サーバーは以下の 2 つのレスポンスのどちらかを返すと仮定しましょう。
{"name":"kotlinx.serialization"}
/* ...or: */
{"title":"kotlinx.serialization"}
name と title は、ともに同じ意味を持っているため、これらを私たちの Kotlin クラス内にある同じフィールドにマッピングしたいとします。 新しい @JsonNames アノテーションを使用すれば、title を name キーの代替キーとして指定することができます。
@Serializable
data class Project(@JsonNames("title") val name: String)
これは、エンコーディングとデコーディングの両方でフィールドの名前変更を許可する一方で、代替の指定は許可しないという @SerialName アノテーションとは異なることに注意してください。
この機能により、同じ値を意味するが違う名前を持つフィールドを返すサービスの操作やスキーマの移行、アプリケーションのスムーズなアップグレードが簡単に行えるようになることを期待しています!
新しくなった API ドキュメント
kotlinx.serialization をできるだけ安心して、楽しく学んでいただけるよう、当社は数多くの参照資料を提供することに努めています。 その 1 つが Kotlin Serialization Guide on GitHub です。ライブラリが提供する機能の手引きとなっており、大切なポイントをすべて盛り込んだ例がいくつも含まれているため、各機能を直感的に理解できるなっています。
他にも、全面的に改訂した kotlinx.serialization API documentation があります。 Kotlin のドキュメンテーションエンジン Dokka の最新バージョンに基づき、新しい API ドキュメントには、新しいレスポンシブかつモダンなデザインや理解しやすいシンボルが採用されています。

kotlinx.serialization の新しくなった API ドキュメントを詳しくご覧ください!
Protobuf: Kotlin クラスからのスキーマ生成の実験的サポート
Protocol Buffers (Protobuf) は、Google が開発したバイナリシリアル化の形式であり、構造化されたデータに使用されます。 バイナリ形式であるため、JSON や XML よりも空間効率が優れていると同時に、アプリケーション間でのコミュニケーションに使用できる言語に依存しない構造を提供します。
kotlinx.serialization では、実験的安定性(experimental)としてマルチプラットフォーム対応の Protobuf を使ったシリアル化 (proto2 セマンティクスを使用) を行えます。 他の形式と同様に、クラスは @Serializable として注釈し、ビルトインメソッド encode / decode を使用します。
@Serializable
data class Project(val name: String, val language: String)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
val bytes = ProtoBuf.encodeToByteArray(data)
println(bytes.toAsciiHexString())
val obj = ProtoBuf.decodeFromByteArray(bytes)
println(obj)
}
Kotlin クラスをいわゆる信頼できる情報源(source of truth)とし、また便利なカスタマイゼーションも使用することにより、 kotlinx.serialization は、データのバイナリスキーマを推論することが可能です。これによりProtobuf コミュニケーションを複数の Kotlin アプリケーション間で簡潔で便利に行うことができるようになります。
kotlinx.serialization 1.2 には、Protocol Buffers の実験的なスキーマジェネレーターも搭載されました。 Kotlin のデータクラスから .proto ファイルを生成することができます。また、それを使って Python や C++, TypeScript など、他の言語でコミュニケーションスキーマを表現することができます。
新しいスキーマジェネレーターの使用を開始する手順については、ドキュメントの該当する手順をご覧ください。
.proto ファイルが生成されたら、リポジトリに保管し、他の言語で表現された Kotlin クラスを生成することに使用できます。 これにより、Kotlin のソースコード内で直接スキーマを管理できるという利便性を維持しながら、複数言語のアプリケーションでも kotlinx.serialization が提供する Protobuf との統合を簡単に活用できるようになることを期待しています。
これは Protobuf スキーマジェネレーターの最初のイテレーションということもあり、皆さまからのフィードバックを特に重要視しています。 是非ともお試しください。皆さまのユースケース、モデルや .proto ファイルの管理方法、直面した問題、あればいいなと思われる機能などを GitHub の課題トラッカーより知らせください。
スキーマジェネレーターを使用する際は、いくつか制限がありますので覚えておきましょう。 大まかな原則としては、kotlinx.serialization に搭載されている protobuf の実装を使って Kotlin クラスをシリアル化できる場合は、スキーマジェネレーターがそれをサポートするようになっています。 これは、同じ制限が適用されるということでもあります。 以下、注意点をいくつか紹介します。
- Kotlin のクラス名とプロパティ名は、protobuf の仕様に準拠する必要があり、不正な文字を含まない。
- Kotlin の null 許容性はスキーマに反映されない (proto2 はそれ専用のセマンティクスを持たないため)。 Protocol Buffer が提供するオプションのフィールドは、Kotlin のプロパティがデフォルト値を定義するかどうかに基づいて使用される。
- Kotlin のデフォルト値はスキーマに含まれない。 (つまり、別の言語での実装においてもデフォルト値の一貫性を自ら保証する必要があります。)
kotlinx.serialization 1.2 をご使用ください!
本リリースの概要は以上です! JSON の高速化されたエンコーディング・デコーディング機能 や Kotlin 1.5 で新たに追加された型システムのサポート、Protobuf のスキーマ生成などをさっそく活用したいという方は、今すぐアップグレードしてください!
kotlinx.serialization を既に使用されている方は、バージョン 1.2 にすばやくアップグレードしていただけます (kotlinx.serialization をまだお試しでない方は、是非このタイミングで始めてください!) まずは、build.gradle.kts ファイルの plugins ブロックを更新します。
plugins {
kotlin("jvm") version "1.5.0" // or kotlin("multiplatform") or any other kotlin plugin
kotlin("plugin.serialization") version "1.5.0"
}
そして、ランタイムライブラリで dependencies ブロックを更新し、アプリケーションで使用する形式なども一緒に更新します。
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-serialization-json:1.2.1")
implementation("org.jetbrains.kotlinx:kotlinx-serialization-protobuf:1.2.1")
// . . .
}
動画とその他の情報
- kotlinx.serialization 1.2 の動画
- GitHub のライブラリ
- kotlinx.serialization 使用ガイド
- API ドキュメント
- Kotlin 1.5.0 リリースに関するブログ記事
問題に直面した場合
- 問題を GitHub の課題トラッカーに報告する。
- Kotlin Slack の #serialization チャンネルでヘルプを求める (招待を受ける)。
Kotlin YouTube チャンネルにご登録ください! 楽しく (デ) シリアル化しましょう!