kotlinx.serialization 1.2 is out! The latest version of our multiplatform serialization library brings a number of improvements – here are the highlights:
- JSON serialization is faster than ever before. Version 1.2 is up to twice as fast as previous versions when parsing JSON into type-safe Kotlin objects and turning Kotlin objects into their text representations.
- Kotlin 1.5 type system additions are now supported. Value classes and unsigned numbers can be turned into JSON and back just like any other Kotlin class.
-
New API documentation makes it easy to discover all the functionality
kotlinx.serializationhas to offer.
Version 1.2 also includes new support for alternative names for JSON fields, and it provides a new experimental approach that automatically generates Protobuf schemas from Kotlin classes, a feature for which we’re eager to receive your feedback!
Let’s explore the changes and additions in this new version together! If you’re already convinced, you can of course also jump directly to the upgrade instructions below!
Start using kotlinx.serialization 1.2!
Faster-than-ever JSON encoding and decoding
The ability to encode Kotlin classes to JSON strings and the ability to turn JSON strings into Kotlin classes are the most commonly used features of kotlinx.serialization, and we’re constantly working to improve their performance.
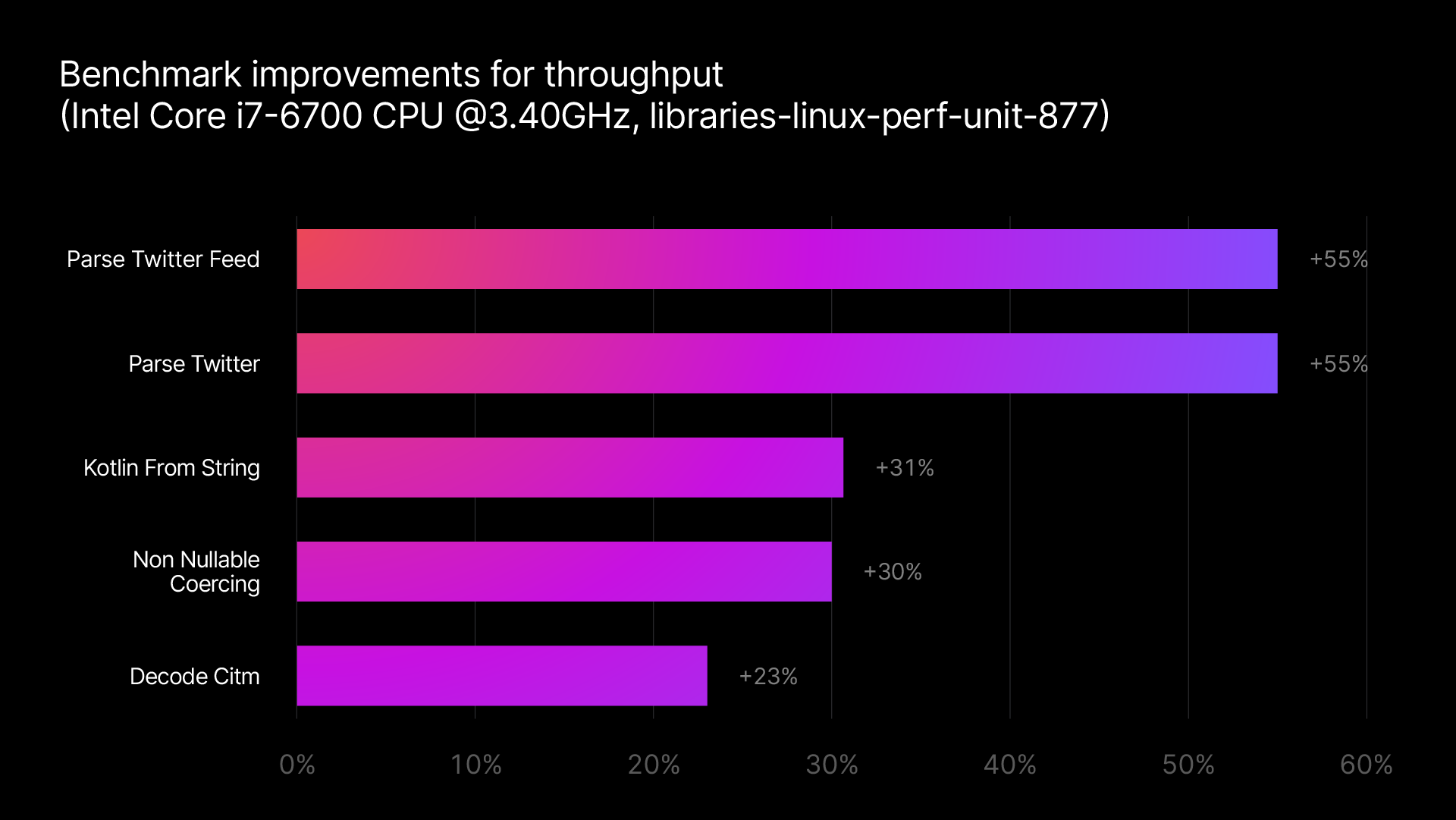
Version 1.2 completely overhauls the internal structure of kotlinx.serialization, resulting in significantly better performance for this core functionality. We have rewritten our JSON decoder (responsible for turning text into Kotlin objects), and we’ve made significant optimizations to our JSON encoder (responsible for turning Kotlin objects into text).
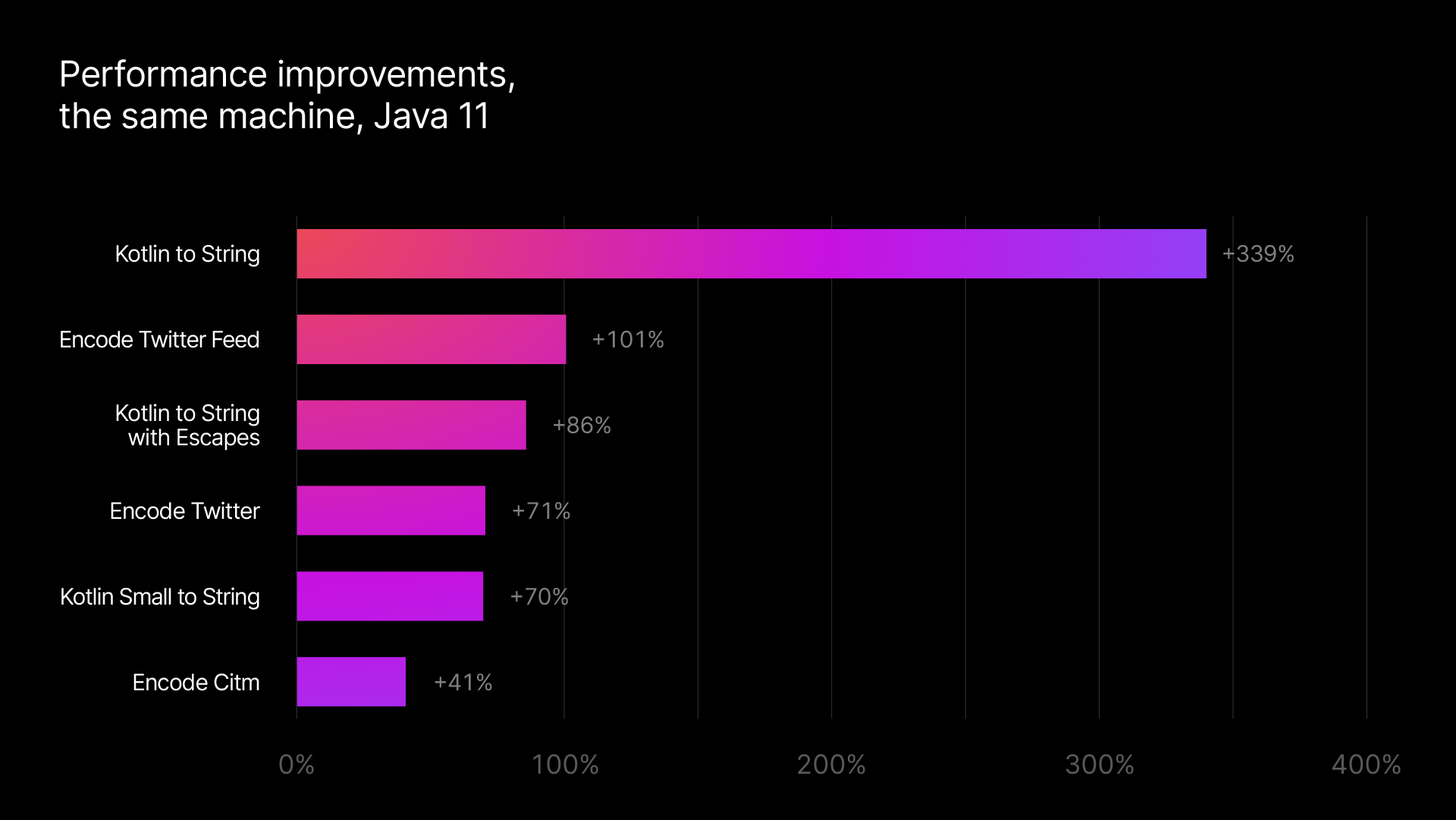
Just by upgrading to the latest version of our library, you can expect up to double the speed for typical encoding and decoding tasks. (As you can see, some of our internal benchmarks, which were particularly affected by these new optimizations, even exceed that number!)
With these changes, kotlinx.serialization achieves (and in some ways exceeds) performance parity with other JSON libraries right out of the box. Even the simplest snippets benefit from this overhaul:
@Serializable
data class User(val name: String, val yearOfBirth: Int)
fun main() {
// Faster encoding...
val data = User("Louis", 1901)
val string = Json.encodeToString(data)
println(string) // {"name":"Louis","yearOfBirth":1901}
// ...and faster decoding!
val obj = Json.decodeFromString(string)
println(obj) // User(name=Louis, yearOfBirth=1901)
}
The best way to get a feeling for these improvements is to benchmark your own application with the newest version of our library. For some rough performance numbers, you can have a look at our internal benchmarks for encoding and decoding, which compare the latest version of kotlinx.serialization to its previous release.
Stable JSON (de)serialization for value classes and unsigned number types
Kotlin 1.5.0 provides two exciting additions, value classes and unsigned integer types, for which kotlinx.serialization 1.2 now offers first-class JSON encoding and decoding support. Let’s take a closer look.
Support for value classes
Value classes (formerly called inline classes) are a way to wrap another Kotlin type (for example, a number) in a type-safe manner without introducing additional runtime overhead. This helps make your programs more expressive and safe without incurring performance penalties.
kotlinx.serialization’s built-in JSON serialization now works for value classes. Just like other Kotlin classes, we just have to annotate a value class with @Serializable.
@Serializable value class Color(val rgb: Int)
Value classes are stored (and serialized) directly as their underlying type. We can see this by adding a field with a value class type to a serializable data class, and inspecting its output:
@Serializable
data class NamedColor(val color: Color, val name: String)
fun main() {
println(Json.encodeToString(NamedColor(Color(0), "black")))
}
// {"color": 0, "name": "black"}
In the example above, NamedColor treats the value class Color as the underlying primitive (an Int). This means you get to enjoy maximum type-safety inside your Kotlin code, while still benefiting from a concise serialized representation of these types, without unnecessary boxing or nesting.
We’re still refining the design for hand-written, custom serializers for value classes, and they remain experimental for now. You can find out more on this topic in docs on GitHub.
Support for unsigned integers
Unsigned integers are an addition to the Kotlin standard library that provide types and operations for non-negative numbers. With the release of Kotlin 1.5.0, the following unsigned number types are available:
-
UByte, with values from 0 to 255 -
UShort, with values from 0 to 65535 -
UInt, with values from 0 to 2^32 – 1 -
ULong, with values from 0 to 2^64 – 1
The JSON encoder and decoder in kotlinx.serialization now supports these types out of the box. Just like other number types, unsigned integer values will be serialized in their plain number representation (the same representation you see when invoking .toString), without truncation, wrapping, or conversion to signed types.
@Serializable
class Counter(val counted: UByte, val description: String)
@Serializable
class BigCounter(val counted: ULong)
val counted = 239.toUByte()
println(Json.encodeToString(Counter(counted, "tries")))
// {"counted":239,"description":"tries"}
println(Json.encodeToString(BigCounter(ULong.MAX_VALUE)))
// {"counted":18446744073709551615}
Please note that support for value classes and unsigned integers is currently available for JSON. In a future release, we will also provide direct integrations for CBOR and Protobuf – stay tuned!
If you want to stay up-to-date with future releases of kotlinx.serialization and the Kotlin programming language, subscribe to the Kotlin product updates newsletter via the form next to this blog post!
For more detailed information on using value classes and unsigned types with kotlinx.serialization, have a look at the documentation on GitHub.
Alternative name support for JSON fields
Sometimes, you need to parse JSON fields that have different names but the same meaning, for example, to maintain backwards compatibility. With the new @JsonNames annotation, you can now give JSON fields alternative names, which will be used during the decoding process.
To illustrate this, let’s look at an example. Let’s assume that depending on its version, a server gives us one of the two following responses:
{"name":"kotlinx.serialization"}
/* ...or: */
{"title":"kotlinx.serialization"}
Both name and title have the same meaning, and we want to map them to the same field in our Kotlin class. With the new @JsonNames annotation, we can specify title as an alternative key for the name key:
@Serializable
data class Project(@JsonNames("title") val name: String)
Notice how this is different from the @SerialName annotation, which allows you to rename fields for both encoding and decoding, but does not allow you to specify alternatives.
We hope that this feature will make it easier for you to work with services that return differently named fields representing the same values, survive schema migrations, and provide graceful upgrades for your applications!
Fresh API documentation
To make your experience learning kotlinx.serialization as comfortable and fun as possible, we try to provide you with a number of reference materials. One of them is the Kotlin Serialization Guide on GitHub, which offers a walkthrough for the functionality provided by the library and includes self-contained examples to give you an intuitive understanding of each feature.
Another is the kotlinx.serialization API documentation, which we have completely overhauled. Based on a new version of Dokka, the Kotlin documentation engine, the new API documentation comes in a new responsive and modern design and easy-to-navigate symbols.

Explore the new kotlinx.serialization API documentation!
Protobuf: experimental schema generation from Kotlin classes
Protocol Buffers (Protobuf) is a binary serialization format for structured data created by Google. As a binary format, it is more space-efficient than JSON or XML, while still providing a language-agnostic structure which you can use for application-to-application communication.
With kotlinx.serialization, you can use multiplatform Protobuf serialization (using proto2 semantics) with experimental stability. Like the other formats, you annotate your class as @Serializable and use the builtin encode / decode methods:
@Serializable
data class Project(val name: String, val language: String)
fun main() {
val data = Project("kotlinx.serialization", "Kotlin")
val bytes = ProtoBuf.encodeToByteArray(data)
println(bytes.toAsciiHexString())
val obj = ProtoBuf.decodeFromByteArray(bytes)
println(obj)
}
With your Kotlin classes as the source of truth (together with any customizations you might want to apply), kotlinx.serialization is able to infer the binary schema of the data, making Protobuf communication between multiple Kotlin applications concise and convenient.
kotlinx.serialization 1.2 now also includes an experimental schema generator for Protocol Buffers. It allows you to generate .proto files from your Kotlin data classes, which in turn can be used to generate representations of your communication schema in other languages, including Python, C++, and TypeScript.
For instructions on how to get started with the new schema generator, check out the corresponding instructions in the documentation.
Once the .proto file has been generated, you can store it in your repository and use it to generate representations of your Kotlin classes in other languages. We hope that this will make it easier for you to use kotlinx.serialization’s Protobuf integration in multi-language applications without having to give up the convenience of managing your schemas directly in Kotlin source code.
Because this is the first iteration of the Protobuf schema generator, we heavily rely on your feedback. Please give it a try, and tell us about your use cases, how you manage your models and .proto files, any problems you encounter, and the features you’d like to see, using the GitHub issue tracker.
When working with the schema generator, please keep some of its limitations in mind. As a rule of thumb, if a Kotlin class can be serialized with the protobuf implementation included with kotlinx.serialization, then the schema generator will provide support for it. This also means that the same restrictions apply. Here are some points to be on the lookout for:
- Kotlin classes and property names need to conform to the protobuf specification, and don’t contain illegal characters.
- Kotlin’s nullability is not reflected in the schema (because proto2 does not have semantics for it). Optional fields as provided by protocol buffers are used based on whether your Kotlin properties define default values.
- Kotlin default values are not included in the schema. (meaning you will have to ensure the consistency of defaults in different language implementations by yourself.)
Start using kotlinx.serialization 1.2!
That concludes our overview! If you’re ready to enjoy faster JSON encoding and decoding, support for Kotlin 1.5 type system additions, Protobuf schema generation, and more, then it’s time to upgrade!
If you’re already using kotlinx.serialization, upgrading to version 1.2 is very quick (and if you haven’t tried kotlinx.serialization before, now is a great time to get started!). First, update the plugins block in your build.gradle.kts file:
plugins {
kotlin("jvm") version "1.5.0" // or kotlin("multiplatform") or any other kotlin plugin
kotlin("plugin.serialization") version "1.5.0"
}
Then, update your dependencies block with the runtime library, including the formats you want to use in your application:
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-serialization-json:1.2.0")
implementation("org.jetbrains.kotlinx:kotlinx-serialization-protobuf:1.2.0")
// . . .
}
Watch and read more
- kotlinx.serialization 1.2 video
- Library on GitHub
- kotlinx.serialization guide
- API documentation
- Kotlin 1.5.0 release blog post
If you run into any trouble
- Report issues to the GitHub issue tracker.
- Look for help in the #serialization channel on the Kotlin Slack (get an invite).
Subscribe to Kotlin YouTube! Happy (de)serializing!